Synology Drive: PDF-Dokumente durchsuchen
![]() von caschy | 23 Kommentare
von caschy | 23 Kommentare
 Ich habe in den letzten Jahren immer mal wieder über mein papierloses Büro berichtet. Ist bei mir recht einfach, Rechnungen versende ich online und oft bekomme ich die auch online. Was ich nicht zwingend benötige, landet in der Tonne, im echten Leben sowie auch digital. Ich bekam oft die Frage, wie ich es mit Datenbanken halte, wie ich also Dokumente verwalte. Die Antwort war immer die gleiche: Gar nicht. Ich brauche keine Datenbanken, um irgendwelche Dokumente wiederzufinden. Dafür ist mein Aufkommen an Dokumenten zu klein.
Ich habe in den letzten Jahren immer mal wieder über mein papierloses Büro berichtet. Ist bei mir recht einfach, Rechnungen versende ich online und oft bekomme ich die auch online. Was ich nicht zwingend benötige, landet in der Tonne, im echten Leben sowie auch digital. Ich bekam oft die Frage, wie ich es mit Datenbanken halte, wie ich also Dokumente verwalte. Die Antwort war immer die gleiche: Gar nicht. Ich brauche keine Datenbanken, um irgendwelche Dokumente wiederzufinden. Dafür ist mein Aufkommen an Dokumenten zu klein.
Ich bin so der klassische Ordner-Typ und wuppe da immer die entsprechenden Dokumente rein. Angebote, Rechnungen, Quittungen, Paketmarken und so. Ich komme damit gut klar. Dann aber folgt immer die Frage nach der Indexierung der Inhalte.
Viele denken ja, dass sie ein Dokument abfotografieren können und es dann immer wiederfinden. Nun, das ist bekanntlich nicht so. OCR ist das Stichwort und da führen viele Wege nach Rom. Viele Scanner oder All-in-Ones können scannen und liefern gleich Texterkennung (OCR) mit.
Alternativ kann man es wie ich machen, sich mobile Apps wie ScanBot oder Scanner Pro von Readdle anschauen. Das sind so meine Favoriten. Dokument abfotografieren, OCR rüberlaufen lassen und auf Wunsch automatisiert irgendwo speichern. Nun zu diesem „irgendwo“ speichern. Wenn ich es irgendwie auf meinem Mac habe, dann indexiert dieser auch Texte.
Über die Spotlight-Suche finde ich also auch Dokumente, wenn ich ein enthaltenes Wort eintippe. Und Windows 10 indexiert bei PDF-Dateien standardmäßig Eigenschaften und Dateinhalte und findet so Texte.
Reicht sicher vielen. Aber ich möchte hier noch einmal kurz auf die Möglichkeiten eingehen, die ein Synology-NAS bietet. Inwiefern andere Hersteller das auch anbieten – keine Ahnung. Synology indexiert auch Texte, also auch eure ocr’ten PDF-Dokumente. Nutzt ihr da die Suche – beispielsweise im neuen Drive – dann findet dieser auch Inhalte von PDF-Dateien.
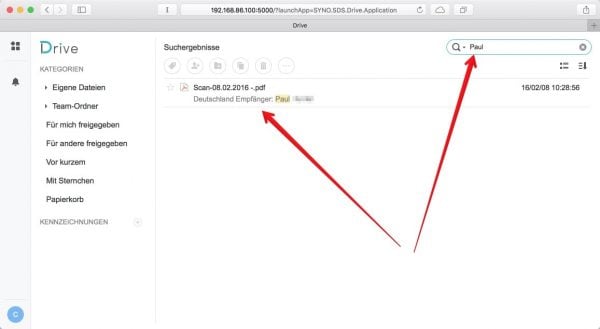
Ihr müsst also nicht zwingend eine fremde Cloud nutzen, geschweige denn etwas auf dem eigenen Rechner ablegen. Und wenn ihr euch daheim mit Frau oder Kindern einen gemeinsamen Büro-Ordner mit entsprechenden Freigaben teilt, dann könnt ihr dort auch alles einmal lagern, aber für alle durchsuchbar. Und praktischerweise kann man sich dann auch gleich eine Verknüpfung zum Synology Drive in die Lesezeichen hauen, um direkt darauf zuzugreifen.
Ist vielleicht nicht grundsätzlich neu (das war auch mit Synology Office machbar) – abgesehen von Synology Drive – aber vielleicht hilft es ja jemandem, seine Papiere auch lose besser zu finden. Und am Rande noch ein kleiner Tipp, falls ihr Dokumente im Nachhinein mit OCR versehen wollt: Es gibt viele Lösungen, ich persönlich habe da PDF OCR X im Einsatz, kostenlos für Windows und macOS.
Auch zum Thema:
Adobe Scan: Kostenlose Scan-App mit OCR








Ich hab zwar keine Synology, sondern die wdmycloud und hoffe, dass es damit auch funktioniert?
Hey, klingt nach einer interessanten Sache, die ich noch nicht kannte. Bin immer mehr beeindruckt von den Möglichkeiten von meinem neuen NAS von Synology.
Bei meinem alten WD Nas habe ich die ganzen Sachen immer per FTP rauf kopiert. Gibt es da bei Synology eine bessere Lösung als den Outputordner von scanbot ab und zu im Hintergrund mit meinem Nas zu synchronisieren? Eventuell eine Einbindung von Drive in die scanbotapp oder so?
Freue mich auf eure Tipps.
Viele Grüße
Max
Ich habe einen Haufen PDF, die noch nicht mit OCR behandelt wurden.
Gibt’s eine zuverlässibe Software für Synology, die PDF auch im nachherein mit OCR behandelt? Muss gar nicht so schnell sein (NAS läuft ja 7*24) aber sollte schon gute Qualität haben und autonom laufen.
Gruß Hank
Ich habe bisher auch immer nur im Dateisystem archiviert. War auch alles immer wiederzufinden. Allein vernünftige Benennung der Dateien war schon ein Segen. Habe dafür TagSpaces verwendet.
Aber ich bin nun dennoch wieder bei Office-N-PDF gelandet. Der Kategorienbaum ist einfach viel praktischer als nur eine Verzeichnisstruktur. Auch das Taggen, das Speichern von Suchanfragen und die schöne Anzeige der PDF-Metadaten. Und es fühlt sich irgendwie datensicherer an. Im Verzeichnis hat man schnell mal eben eine Datei versehentlich gelöscht, in einer Anwendung nicht. Zumindest gefühlt…
Auch finde ich es schöner wenn die Dateien nicht von jedermann schon am Dateinamen interessant erscheinen. Und es ist für mich ebenfalls Datenschutz, wenn ich eine Anwendung brauche, um an die Dateien zu kommen.
Im Übrigen kann Office-N-PDF sehr schön exportieren, es legt die Kategoriestruktur als Verzeichnisstruktur an und die Dateinamen entsprechen den Namen, die man dort im Baum vergeben hat.
Ich nutze schönheit Jahren EcoDMS. Das Speichern 8n Ordnern war mir irgendwann zu unübersichtlich.
Ich nutze OneNote als „Pseudo-Dokumentenmanagement“. OneNote hat eine OCR-Engine integriert. Eingefügte Scans oder PDFs werden – sofern aktiviert – automatisch nach Text durchsuchbar gemacht. Das funktioniert tadellos, selbst bei unsauberen Originalen. Da brauche ich kein echtes Dokumentenmanagement.
In der kostenlosen Version kann man leider die Notizbücher nur auf der OneDrive speichern, was bei sensiblen Dokumenten natürlich nicht jeder will. Da ich aber das Office-Paket habe, speichere ich meine Notizbücher auf mein NAS.
http://unsortiertes.de/2016/dokumentenarchiv-mit-onenote
Eine übersichtliche Ordner Struktur und ein korrekter Dateiname, mehr braucht man eigentlich nicht… Damit hat man auch keine Probleme mit Backups, ist Plattform und Programme-unabhängig… OCR ist natürlich nice to have… Aber ich hab es bislang nie benötigt und entsprechend werden die gescannten PDFs ohne Aufwand in meine Ordnerstruktur gelegt und fertig… Mach ich seit über 15 Jahren so ohne was zu vermissen… Auch mit Fotos, Musik, Videos etc.
Hallo allerseits, danke für’s Feedback.
Jetzt die Frage, wie macht ihr die Ordnerstruktur?
Versicherungen // Auto / Haftpflicht
Rechnungen // Handwerker / Gekaufte Geräte / —
Wie stelle ich mir das vor? Wie legt ihr den Dateiname fest? (Allianz_KFZ_2016_Golf.pdf) oder wie?
Fotos habe ich streng chronologisch in Ordnerstruktur.
Picasa (als es das noch als App gab) konnte schön die Gesichter taggen und auch die Orte der geocodierten Fotos.
Habe vor einiger Zeit Adobe Elements Organizer 15 gekauft, der größte Sch??ß. So langsam und planlos, geht auf keine Kuhhaut.
Gruß
Werde mir auch eine Synology bestellen.
@Hank Ordnerstruktur ist eigentlich der größte MIst. Lege ich die Rechnung für die Autoversicherung nun in \Versicherungen oder \Autos ab? Oder die Handwerkerrechnungen in \Haus \Wohnung oder \Rechnungen oder \Steuern2017 ab? Will sagen, können an mehreren Orten Sinn ergeben. Und da Betriebssysteme noch immer keine Tags können, bin ich dann doch wieder bei einer Anwendung und nicht Dateisystem. Ok, mal von TagSpaces abgesehen.
@paubolix: Mein System kann Tags.
@caschy Will ich gar nicht wissen. :-)) Aber nicht WIndows? Oder was hast du gemacht?
Ich habeletztes Jahr mal (Dank Cashy) meine PDF’s auf dem Synology gesammelt. OCR wird bei mir mit NAPS2 gemacht. Funktioniert klasse. Sowohl gescannte als auch elektronische PDF’S lassen sich verarbeiten. Einziges Manko ist bist dato, das die Suche als klassischer Windows User nur über die Synology Oberfläche funktioniert. Oder gibt es da mittlerweile einen anderen Weg?
Ich erledige das inzwischen mit Evernote. Kann ich jedem nur sehr ans Herz legen. Funktioniert 1a.
Ich benutze dafür auch Evernote. Die Suche ist klasse.
Hallo Cashy, danke für den Artikel. Interessante Sache. Das gibt es von qnap auch und nennt sich dort OCR converter.
Das werde ich mir mal Ansehen.
@ Hank:
Hier gibt es eine schöne Lösung. Einzige Vorraussetzung: Deine DS muss Docker unterstützen (also mit Intel CPU). Auf diese Weise lasse ich meine PDF’s ocr’en …
Link: http://www.synology-forum.de/showthread.html?21277-pdf-Scan-to-Folder-%28auf-die-Synology%29-und-dann-Texterkennung-mit-OCR-durch-Synology&p=717598&viewfull=1#post717598
Zur Info, für die Synology hab ich mal ein Projekt gestartet. Das kann OCR über sämtliche PDFs laufen lassen und basierend auf Regeln die Dateien umbenennen und hashtaggen.
Mehr Details hier:
http://www.synology-forum.de/showthread.html?21277-pdf-Scan-to-Folder-%28auf-die-Synology%29-und-dann-Texterkennung-mit-OCR-durch-Synology&p=717598&viewfull=1#post717598
Und hier das Projekt:
https://github.com/stweiss/FileBasedMiniDMS
Ist nicht ganz trivial einzurichten, aber die Leser hier kennen sich ja aus 😉
@Max: Zu Deiner Scanbot-Frage: Du kannst direkt beim Scan-Vorgang das Ergebnis an die Synology-App „DS File“ übergeben. Noch geschickter finde ich es via WebDAV und Scanner Pro: Du kannst gleich mehrere Workflows einrichten, so dass der eine Scan zum Pfad NAS-„Quittungen“, der andere zu NAS-„Rechnungen“ usw. geleitet wird (offline-OCR ist auch dabei und recht flott). Hier hatte ich mal eine Anleitung dazu geschrieben: http://digital-cleaning.de/index.php/multi-workflow-todoist-und-scanner-pro-ios/
Danke für den tip!
Wie archivierst du Websites die du später lesen willst? Bzw dauerhaft offline speichern?
Auch als PDF?