OCR von PDF-Dokumenten auf dem Synology-NAS
![]() von caschy | 41 Kommentare
von caschy | 41 Kommentare
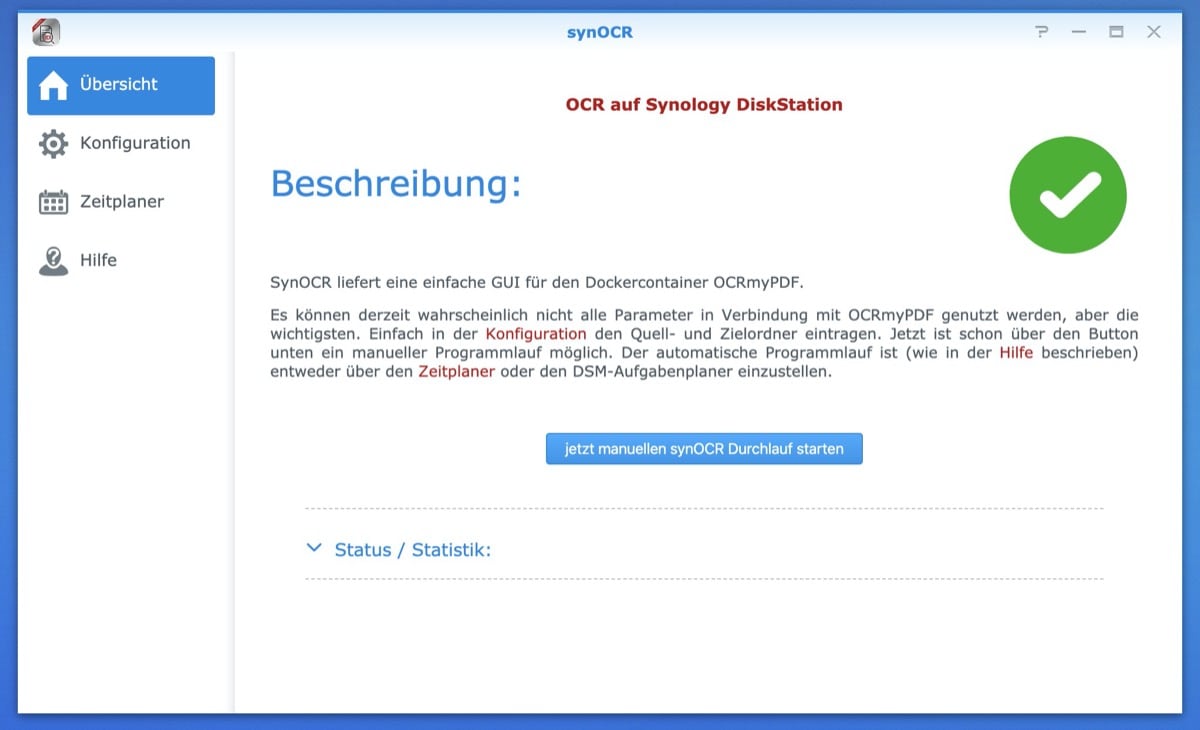
Kleiner Tipp für alle Besitzer eines Synology-NAS. Die Geräte eignen sich ja mittlerweile zu viel mehr als zum Speichern von Daten, da gibt es ja diverse Dienste und Services, die man nutzen kann. Bei mir ist unter anderem der Medienserver Plex im Einsatz, aber auch Homebridge für das Smart Home. Homebridge setzt Docker voraus und sofern euer NAS Docker-kompatibel ist, könnt ihr euch Folgendes bei Interesse anschauen: synOCR.
Das ist eine Oberfläche für eine Texterkennungs-Software namens OCRmyPDF, um PDF-Dokumente durchsuchbar zu machen. Ihr kennt das sicher: Manche PDF-Dokumente sind durchsuchbar, manche nicht. Ich für meinen Teil möchte sie durchsuchbar haben, damit ich meine Dokumente, bzw. deren Inhalte schnell finde. Persönlich setze ich seit Jahren nicht auf einen Dokumentenscanner, mir reicht das Smartphone. Da gibt es diverse Apps mit OCR-Unterstützung, ich selber nutze Scanbot Pro.
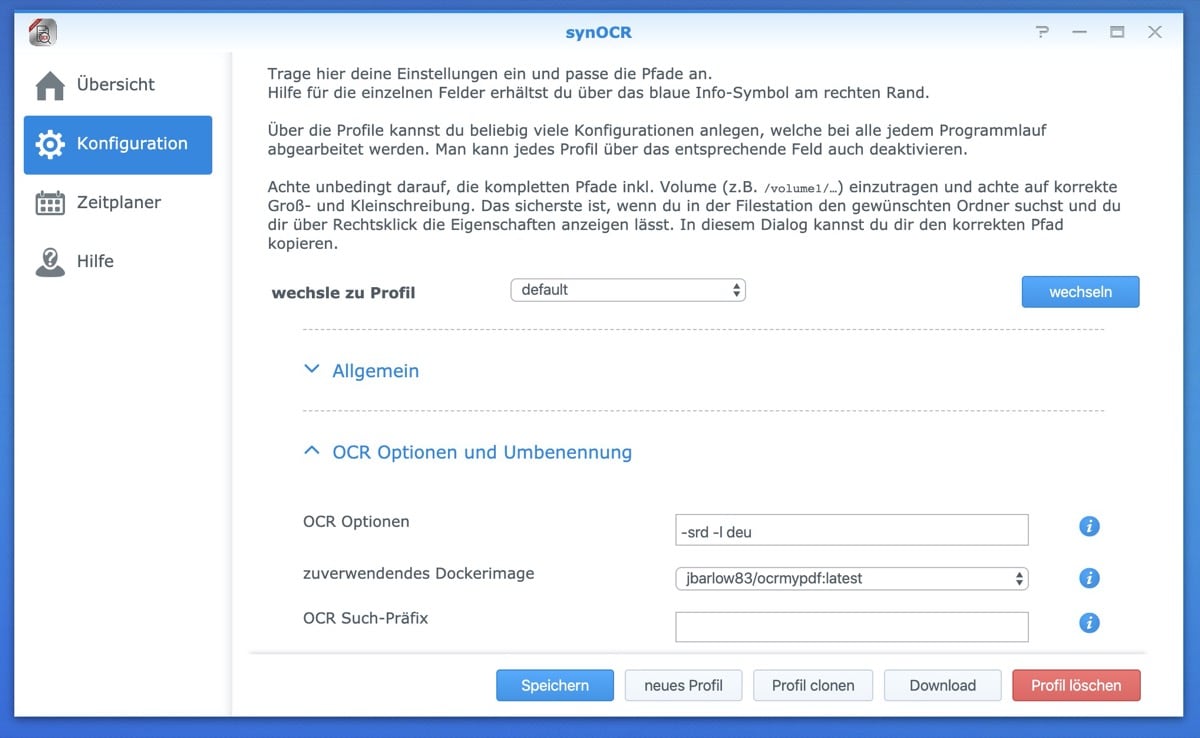
Ich habe keine Datenbank-Software, lege also nur Dokumente in Ordnern ab. Suche ich etwas, so finde ich dies anhand von Ordnern oder eben OCR. synOCR (übrigens Open Source) eignet sich für alle, die viele, nicht „OCRte“ Dokumente haben und diese mit dieser versehen wollen. Das Modul kann manuell installiert werden, alternativ über das Hinzufügen einer zusätzlichen Paketquelle.
Die vorzunehmenden Einstellungen sind simpel: Man hinterlegt einen Ordner, in den man Dokumente ohne OCR reinwirft und einen, wo sie wieder mit OCR hereingelegt werden. Wer mag, der kann eine automatische Überwachung dieser Ordner aktivieren. Ich selber habe mir für diesen Beitrag nur den manuellen Schalter angeschaut. Funktionierte alles ganz gut. Wichtig ist: Der erste Vorgang dauert länger.
Dies liegt daran, dass synOCR beim ersten Vorgang das benötigte Docker-Image OCRmyPDF herunterlädt und einhängt. Später geht das schneller, dann wird das Image nur kurz gestartet und am Ende wieder gestoppt. In der Software gibt es noch ein paar Einstellungsmöglichkeiten, so kann man beispielsweise gewisse Dokumente ausschließen, ein Blick lohnt sich also.
Hier ein paar generelle Links zum Thema:
ScanSnap iX1500 angeschaut – Der Helfer beim Aufbau des papierlosen Büros
PDF oder Bilder: OCR-Texterkennung nachträglich
PDFify: Verkleinert nun PDF-Dateien und importiert direkt über die iPhone-Cam Inhalte
Synology Drive: PDF-Dokumente durchsuchen
Howto: PDF-Dokumente kostenlos unter Windows per Stempel-Werkzeug unterzeichnen
Dokumente mit Notiz-App scannen und unterschreiben
Vorschau-App unter OS X: PDF unterschreiben
Sowas habe ich gesucht. Danke.
Jetzt fehlt mir noch etwas, was die PDFs gerade ausrichten kann. Geht das damit auch?
Ja, geraderichten und drehen wird unterstützt
Interessant bis zu dem Teil, wo docker erwähnt wird und somit für Besitzer kleinerer Synology Systeme leider uninteressant 🙁
Warum? 218+ und gut ist.
Danke, dafür liebe ich deinen Blog für so gute neue technische Sachen.
Für alle die viel ocrpdf benötigen folgende Empfehlung: ein Windows Ordner der automatisch über den Scanner befüllt wird, oder befüllt wird mit email2folder.
Dann vom a-pdf “ Scan ans Split “ um die weißen leeren Seiten zu entfernen, dann von abbyy finereader das Programm „hotfolder“ um OCR drüber laufen zu lassen und die Seiten richtig auszurichten (verkehrt herum eingescannte). Das alles funktioniert problemlos vollautomatisch und so kann man sehr sehr viel Dokumente automatisch und prozesssicher verarbeiten, ausrichten, ocren.
Dieses Setup kann auch in einem Container auf einer virtuellen Maschine laufen.
Hotfolder ist aber erst in der Coporate Edition für 299€ inkludiert. Sehr gute Lösung aber schweine teuer.
Ich hab 2 Syn-NAS, eins welches möglichst viel Schläft und gewisse Sachen täglich erledigt (4-bay) und ein anderes kleines welches permanent online ist (1bay) und eher als proxy fungiert. Leider unterstützt das schwache Syn kein Docker :(( Aber schöne Sache mit dem OCR, danke für die Info
Bin da nicht so bewandert. Wäre es auch möglich dann den Dateinamen automatisch nach einem bestimmten Schema zu benennen? Das finde ich immer nervig bei z.B. Rechnungen.
Begrenzt geht das.
Sobald aber alle PDFs durchsuchbar sind, orientiert man sich (aus meiner Erfahrung) kaum noch am Dateinamen. Bei mir liegen alle Dokumente lediglich nach Jahren sortiert in Ordnern. Die Volltextsuche (macOS Spotlight oder Synology Universal Search) fördern das begehrte zu Tage.
Grundsätzlich hast du da natürlich recht. Aber meine Rechnung würde ich schon gern noch mit Datum versehen nachdem einscannen. Klar inhaltlich sucht man konkret per OCR
Man hätte erwähnen können, dass synOTR mehr oder weniger aus diesem Script hervorgegangen ist:
https://github.com/stweiss/FileBasedMiniDMS
Mehr Details hier:
http://www.synology-forum.de/showthread.html?21277-pdf-Scan-to-Folder-%28auf-die-Synology%29-und-dann-Texterkennung-mit-OCR-durch-Synology&p=717598&viewfull=1#post717598
Es gibt zwar keinen Installer, ist aber nicht schwer einzurichten und eine regelbasierte Namensvergabe ist dabei.
Sorry, nicht synOTR.. synOCR
Großartig, vielen Dank! Gerade weil ich nur am Drucker scanne, find das deutlich praktischer als alle anderen Lösungen, es geht schneller, Duplex, braucht kein zusätzliches Gerät und vor allem PC unabhängig Canon MB5500 oder HP 8730, klappt mit beiden grob mit 20 Seiten Duplex die Minute).
Perspektivisch wird OCR sicher bald auch mit Heimgeräten gehen (unsere neuen Lexmark Kopierer auf der Arbeit machen OCR gleich mit, ich war sehr begeistert!), aber ich habe ja noch viele PDFs ohne OCR und will den Drucker gerne noch länger nutzen… Von daher: genau sowas hat mit noch gefehlt!
Ich habe SynOCR vor einiger Zeit auch schon probiert, allerdings waren bei mir die PDF-Dateien danach wesentlich größer. Aus 1 MB wurden da auch mal 10 MB oder mehr. Somit war dieser Container für mich nicht nutzbar. Ob sich das mittlerweile gebessert hat weiß ich nicht.
Jetzt verwende ich jbarlow83-ocrmypdf. Die Konfiguration ist nicht so komfortabel aber wenn man mal alles eingerichtet hat klappt es super. Auch für den Dateinamen kann man vorgaben machen.
Danke für den Tipp. Aber ich denke einen neuen Versuch werde ich mit SynOCR nicht starten. Bin mit meiner Lösung sehr zufrieden. Vom Scanner werden die Dateien direkt auf dem NAS abgelegt und ein Mal täglich (nachts) läuft dann das jbarlow OCR drüber. Das funktioniert jetzt seit über einem Jahr perfekt, deshalb halte ich ich mich lieber an die alte Weisheit „never touch a running system“ 😉
am besten zusammen mit diesem Docker DMS-Projekt mergen: https://github.com/bevuta/pepa
wie kann es sein, dass ich dies auf meiner 418 nicht installieren kann?
Gibt es alternativen?
Auf der 218+ kann man es installieren, aber es erfolgt ein Absturz beim Starten.
Sorry mein Fehler.
Läuft hier ohne Probleme
bei mir auch, wie hast den container starten können
Leider fehlten mir hier die Beschreibung wie es gemacht wird. (übrigens, gerade ziehen macht das auch gleich mit)
Hier eine kleine Anleitung:
1. Gehe ins Packetzentrum
2. Istalliere Docker
3. Gehe auf Einstellungen/Packetquellen (Immernoch im Packetzentrum)
4. Füge http://www.cphub.net als Quelle Hinzu (Name ist dir überlassen)
5. Installiere aus neuem Reiter „Community“ „Synocr“
6. Öffne Docker
7. Suche unter Reiter Registrierung den Punkt „jbarlow83/ocrmypdf“ und installiere
8. Unter Abbild/Container den Container aktivieren
9. öffne synocr und folge den Anweisungen (Lege deine Pfade fest und was du gemacht haben willst und einen Zeitplan wann es gemacht werden soll)
Beachte Resourcenverbrauch.
Viel Spaß
Vielen Dank für die Anleitung
INFO: die Schritte 6 bis 8 sind nicht nötig (Nr.8 bringt gar nichts, da der Container ohne Parameter nicht lauffähig ist).
Der Ressourcenverbrauch betrifft nur die Zeit für die Verarbeitung der Dateien.
der Container startet nicht, bricht direkt ab
hast du eine Idee warum?
Hab ich dir doch schon beantwortet – gleich hier drunter …
der Cointer startet nicht, bricht direkt ab
hast du eine Idee warum
Wenn du keine PDFs zu bearbeiten hast, braucht der Container doch auch nicht zu starten…
Deshalb schrieb ich ja bzgl. der Anleitung, dass die Schritte 6 bis 8 unnötig, bzw. kontraproduktiv sind.
das heißt der startet wenn dort dokumente drin sind oder wie soll ich das verstehen
Darum kümmert sich das Paket synOCR. Wenn in synOCR der OCR-Vorgang ausgelöst wird (entweder manuell über den Button oder, wie in der Hilfe beschrieben, nach Zeitplan), wird von synOCR der entsprechende Container mit den zu bearbeitenden PDFs gestartet. Sind die Dokumente fertig, so wird der Container automatisch wieder gelöscht. Wenn du synOCR verwendest, brauchst du dir um den Container keine Gedanken zu machen.
das habe ich versucht, funktioniert nicht.
Das heisst ich muss den container erst gar nicht inst.
Docker muss installiert sein – mehr nicht. Deinen selbst erstellten Container kannst du löschen.
ok habe ich gemacht, der Docker ist inst. da ich dort andere Programme laufen habe.
Ich habe jetzt mal ein Dokument in den Input gelegt und manuell gestartet. Da passiert aber nichts, es sollte doch dann um output erscheinen
Wenn alles richtig läuft, ja. Da beim ersten Programmlauf zunächst das Image geladen werden muss, dauert der etwas länger (aber das Image sollte ja bei dir eh schon da sein).
Was steht im LOG?
Stimmen die Pfade (Groß- Kleinschreibung beachten)?
Können wir das bitte im Forum fortsetzen (Link am Ende des Beitrags)? Das ist nicht der passende Ort hier.
ok, in welchem forum, sehe keinen Link
Direkt unter dem Hauptartikel „Hier ein paar generelle Links zum Thema:“
(ich weiß nicht, ob URLs im Kommentar gefiltert werden: geimist.eu/link/synocrforum)
Hi Zusammen,
mittlerweile läuft das Teil supper, sprich erkennen etc.
Was nun echt mühsam ist und da habe ich n och nirgends eine Lösung gefunden ist die richtigen Begriffe zu finden damit die Dateinamen richtig erstellt werden.
Wäre toll wenn es irgendeine KI dafür gibt.
Jemand eine Idee?
Ich nutze das Ganze für Devonthink…Devonthink könnte dass ja selber aber mit dem match feature ist es zu aufwendig da für jeden match eine neue Regel erstellt werden muss.
Best Theo
Eine Anmerkung von mir als QNAP Benutzer: Auf QTS gibt’s was ähnliches, das heißt „OCR Converter“ und ist kostenlos im AppCenter verfügbar. Nach erster Prüfung scheint es den Job ganz passabel zu machen, nur leider gibt es nur Einmal- und zeitgesteuerte Jobs, keine ereignisgesteuerten.
Danke für die vielen extrem hilfreichen (und sehr seltenen) Tipps auf diesem Blog – gefühlt bist du damit ganz weit vorne unterwegs!
Ich habe NextCloud 17 auf meiner DS918+ local installiert und bin auch soweit sehr zufrieden. Allerdings muss man für eine funktionierende Volltextsuche noch einiges von Hand erledigen.
1. NexCloud Search Apps installieren – kein Problem
2. Search Platform (der eigentliche Indexer) installieren – nicht so einfach.
ElasticSearch wird in dem Zusammenhang oft als optimale Search Platform genannt. Synology’s eigene „Universal Search“ App baut scheinbar auch auf ElasticSearch auf – synoelasticd laeuft bei Universal Search im Backgroud.
Weiss jemand, ob man Univarsal Search als Search Provider fuer NextCloud verwenden kann und wie man dies konfiguriert?
Unter DSM 7 Beta ist leider (noch) eine Installation nicht möglich. Es wird die Fehlermeldung angezeigt. „Installation fehlgeschlagen. Das Paket sollte mit einer geringeren Berechtigungsstufe ausgeführt werden. Wenden Sie sich an den Paketentwickler, um die Berechtigungseinstellungen zu ändern.“ Auf DSM 6 funktioniert das Programm einwandfrei. Hat jemand einen Tip wie ich das Programm dennoch unter DSM7 installiert bekomme? Lieben Dank vorab für eure Aufmerksamkeit.
Zur Zeit noch nicht. Aber es gibt ja bisher noch nicht einmal eine DSM 7 Beta, lediglich eine geschlossene Previewversion.
Vielen Dank für deinen Beitrag. Dann werde ich einfach noch ein wenig abwarten, bis jemand eine Lösung hat. Es werde ja bestimmt noch einige andere vor dem Problem stehen.