Dokumentenverwaltung paperless-ng mit Docker auf einem Synology-NAS installieren
![]() von caschy | 82 Kommentare
von caschy | 82 Kommentare
An dieser Stelle möchte ich einmal auf das Open-Source-Projekt paperless-ng von Jonas Winkler hinweisen. paperless-ng ist ein Fork des ursprünglichen Projektes paperless zur Dokumentenverwaltung, welches hier und da Feinschliff erhalten hat. Es ist kostenlos und arbeitet auf unterschiedlichen Plattformen. Grundsätzlich ist es aber kein Programm im klassischen Sinne. Es gibts also keine Datei, die ihr irgendwie „mal eben“ auf euren Rechner herunterladen und ausführen könnt.
In Kurzform: paperless-ng ist eine Dokumentenverwaltung. Ihr könnt Dokumente hochladen, es wird automatisch OCR durchgeführt – und ihr könnt im Browser Dokumente verschlagworten, sortieren und natürlich auch finden. paperless-ng kann auf unterschiedliche Art und Weise betrieben werden, beispielsweise unter Linux oder vielleicht, sofern greifbar, in einem Docker-Container. So wie es viele Möglichkeiten gibt, um paperless-ng zu installieren, so gibt es dann auch viele Funktionen im Projekt. Da empfehle ich euch, vielleicht einmal vorab den Blick in die Dokumentation zu werfen.
Ich möchte in diesem Beitrag tatsächlich nur „kurz“ auf die Installation eingehen, wie ich sie als besonders einfach empfunden habe. Wie eben beschrieben: Viele Wege führen nach Rom. Ich habe da einige Zeit versenkt und bin letzten Endes mit einem Script und einem Docker-Container auf dem Synology-NAS zur ersten Sichtung zufrieden gewesen. Falls ihr das für euch ausprobieren wollt, dann folgt mir gerne. Vorausgesetzt wird ein Synology-NAS sowie ein installiertes Docker-Modul.
Schritt 1: Vorbereitung
Sorgt dafür, dass ihr einen von Docker beschreibbaren Ordner in eurem Synology-Dateisystem habt. Bei mir heißt ein Hauptordner „docker“. Da habe ich den Ordner paperless erstellt. Legt dort drin die beiden Ordner „config“ und „data“ an.
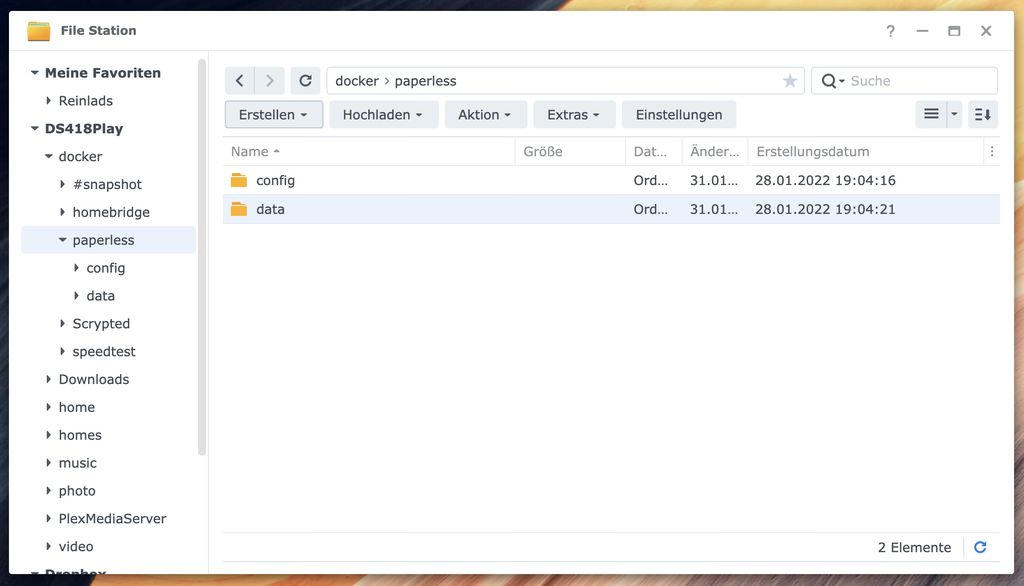
Schritt 2: Container installieren
Geht in eure Systemsteuerung des NAS, ruft den Aufgabenplaner auf. Erstellt eine neue geplante Aufgabe > Benutzerdefiniertes Script.
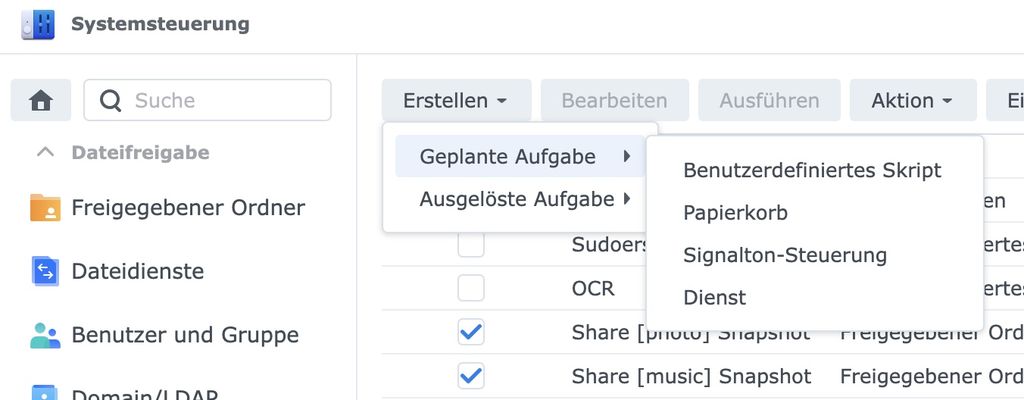
Im Reiter Allgemein stellt ihr den Nutzer auf Root. Bei den Aufgabeneinstellungen muss unter „Befehl ausführen“ folgendes Script eingefügt werden (angepasst aus dieser Anleitung):
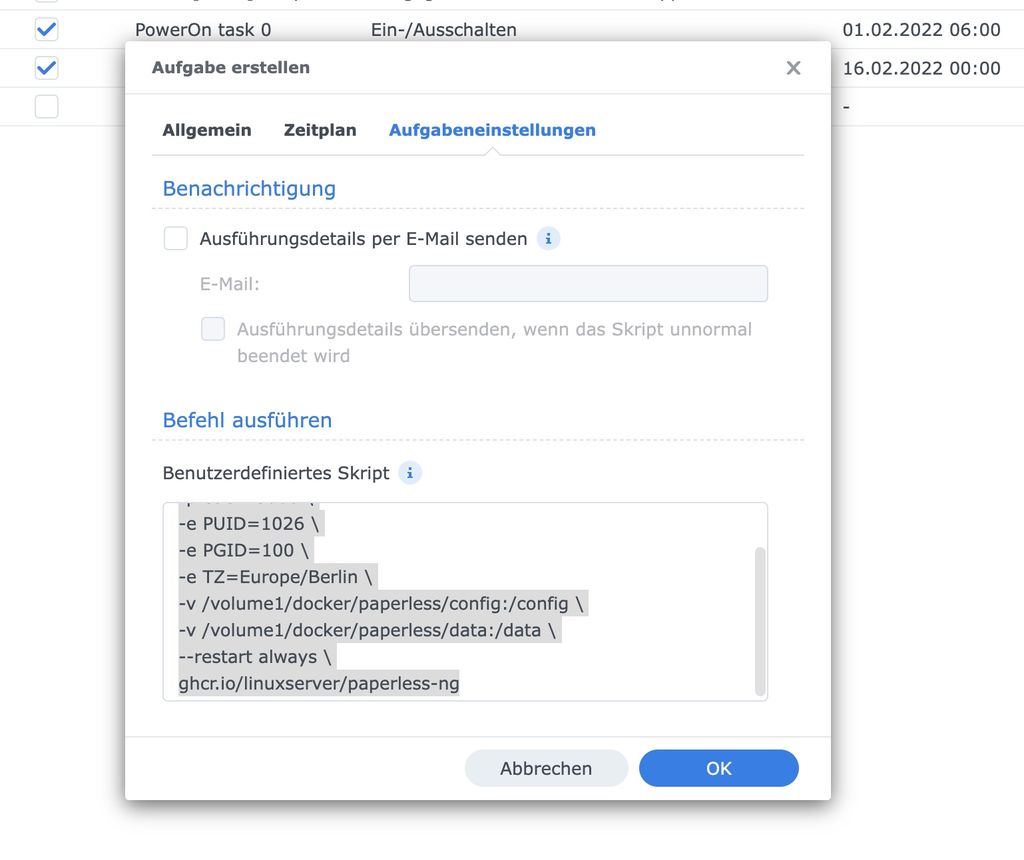
docker run -d --name=paperless-ng \ -p 8931:8000 \ -e PUID=1026 \ -e PGID=100 \ -e TZ=Europe/Berlin \ -v /volume1/docker/paperless/config:/config \ -v /volume1/docker/paperless/data:/data \ --restart always \ ghcr.io/linuxserver/paperless-ng
Grundsätzlich sollte an diesem Script nichts angepasst werden müssen – bei einer Standard-Docker-Installation auf dem NAS sollten PUID und PGID sogar passen. Um euch rückzuversichern, könnt ihr aber schauen, ob das bei euch der Fall ist: Nutzer-ID und Gruppen-ID also wirklich passen. Falls ihr das alles wisst, könnt ihr den kommenden Part jetzt also überspringen und das Script einmalig ausführen.
Systemsteuerung > Terminal & SNMP > SSH-Dienst aktivieren.
Per Terminal über SSH vom Rechner auf dem NAS einloggen. Müsst ihr auf eure IP und Nutzernamen anpassen:
ssh Nutzername@IP-Adresse > Enter und Passwort eingeben. Gebt nun id gefolgt von Enter ein, um Gruppen- und Nutzer-ID zu bekommen.
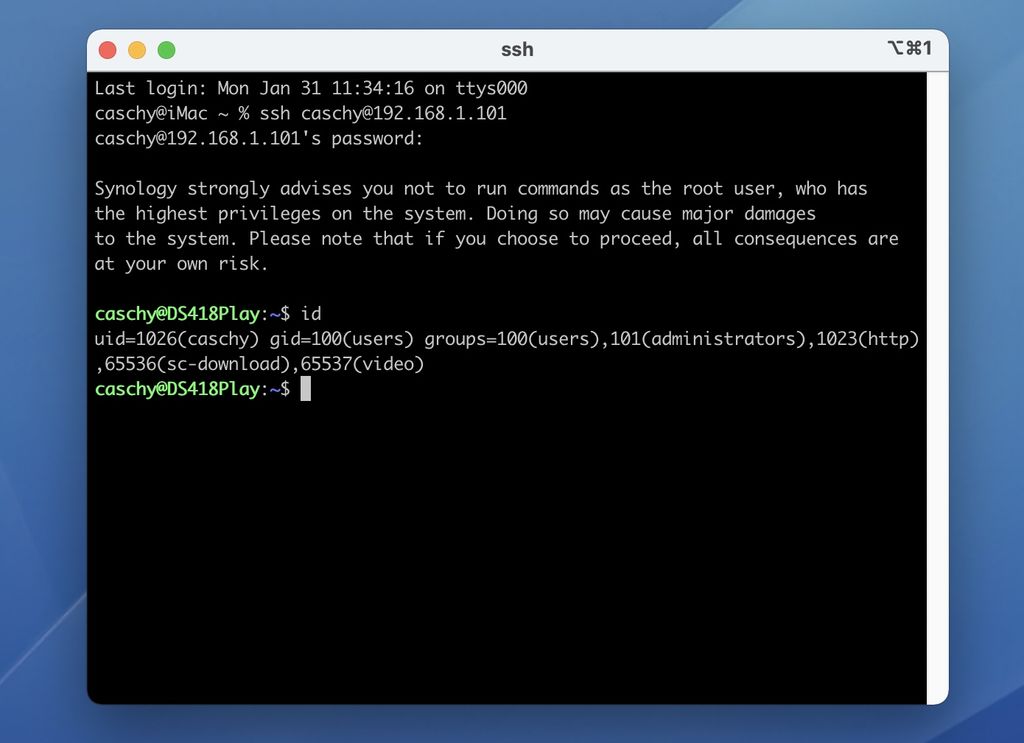
Stimmt mit dem Script überein? Falls nicht – dann eben jetzt anpassen. Danach wieder SSH deaktivieren.
Habt ihr das Script ausgeführt, dann wartet ein wenig. Da müssen das komplette paperless-Paket heruntergeladen und der Docker-Container aufgesetzt werden. Ob der Vorgang beendet ist, lässt sich aber leicht feststellen. Schaut einfach in Docker nach, ob der Container unter „Container“ auch aufzufinden ist. Vorher wichtig:
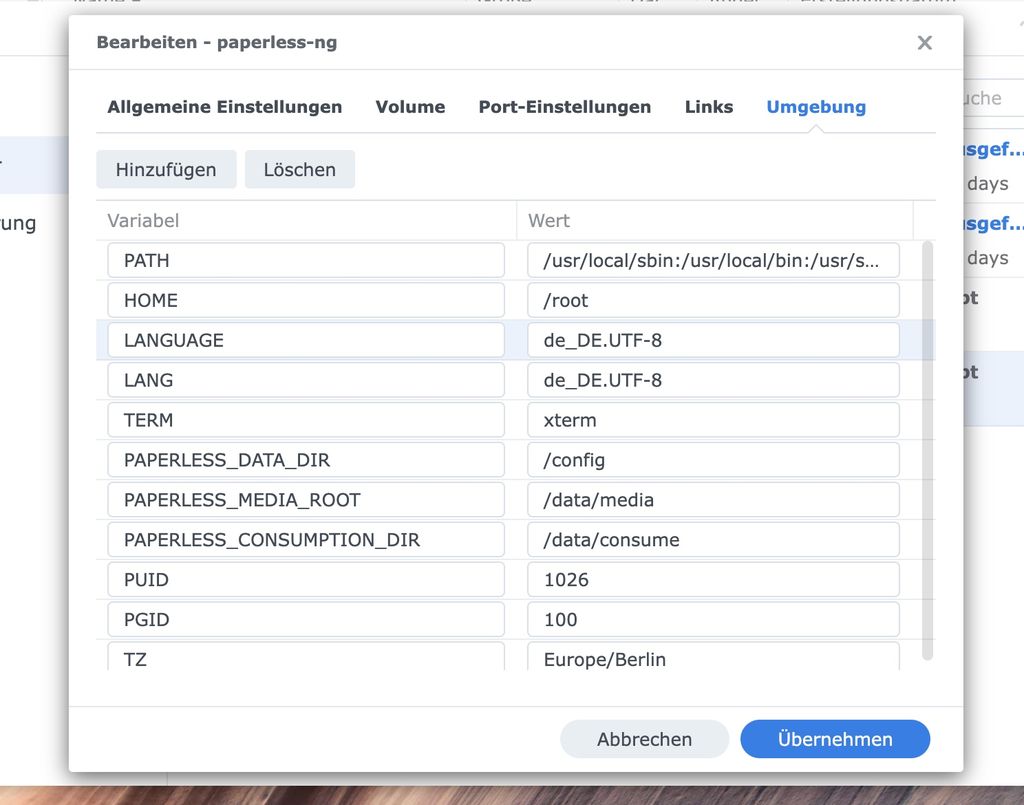
Checkt in der Container-Ansicht noch einmal die Umgebungsvariablen, ob LANG und LANGUAGE auf de_DE.UTF-8 stehen, bzw. vorhanden sind, falls nicht, ändert dies. Danach startet ihr.
Schritt 3: Ersteinrichtung paperless-ng
Anschließend geht’s im Browser weiter. Oben im Script habt ihr vielleicht schon gesehen, dass der Port 8931 genutzt wird. Das ist auch das Geheimnis für den Erstaufruf. Ihr erreicht die App über die IP eures NAS gefolgt von der Porteingabe 8931. Beispielsweise: 192.168.1.101:8931. Das zeigt euch die Oberfläche – und der erste Nutzername nebst Passwort ist admin / admin.
Grundsätzlich könnte ich hier schließen, denn das war die Installation von paperless-ng auf dem Synology-NAS in Docker.
Für den Rest empfehle ich tatsächlich einmal das nackte Ausprobieren sowie ein bisschen Nachlesen auf der Startseite. Grundsätzlich können unterstützte Dateitypen über die Weboberfläche hochgeladen werden, alternativ werft ihr einfach alles in den Unterordner „consume“ auf dem NAS, der sich mittlerweile unter „paperless > data“ befinden sollte.
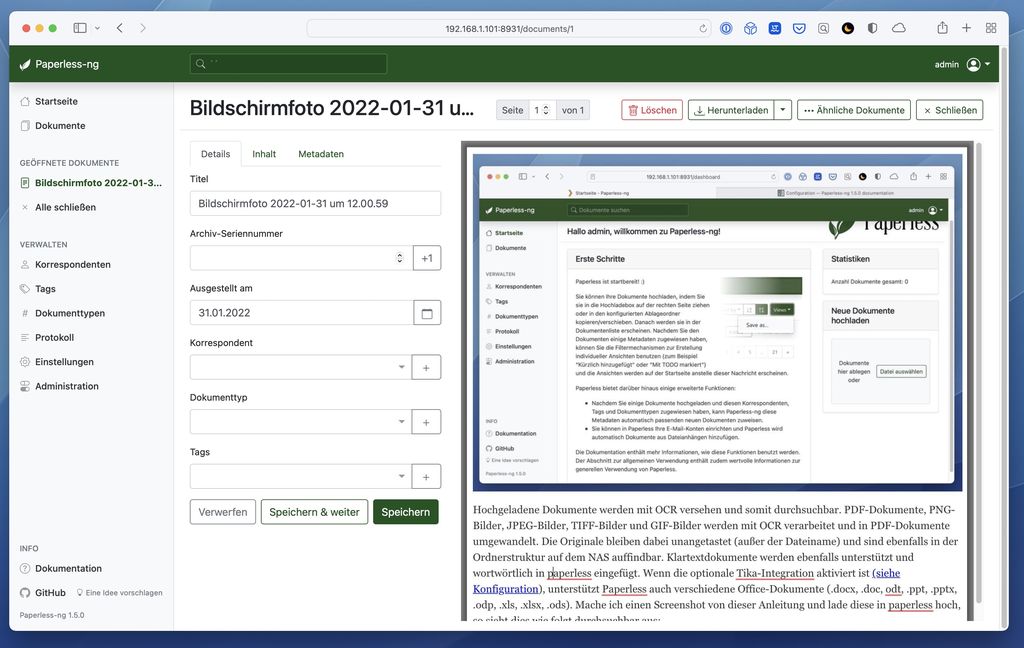
Hochgeladene Dokumente werden mit OCR versehen und somit durchsuchbar. PDF-Dokumente, PNG-Bilder, JPEG-Bilder, TIFF-Bilder und GIF-Bilder werden ebenfalls mit OCR verarbeitet und in PDF-Dokumente umgewandelt. Die Originale bleiben dabei unangetastet (außer der Dateiname) und sind ebenfalls in der Ordnerstruktur auf dem NAS auffindbar. Nach der Verarbeitung sind Dokumente auf dem NAS jeweils im Ordner /docker/paperless/data/media/documents/archive und /docker/paperless/data/media/documents/originals abgelegt. Mache ich einen Screenshot von dieser Anleitung und lade diese in paperless hoch, so sieht dies wie folgt durchsuchbar aus:
Klartextdokumente werden ebenfalls unterstützt und wortwörtlich in paperless-ng eingefügt. Wenn die optionale Tika-Integration aktiviert ist (siehe Konfiguration), unterstützt paperless-ng auch verschiedene Office-Dokumente (.docx, .doc, odt, .ppt, .pptx, .odp, .xls, .xlsx, .ods).
Ab hier überlasse ich euch dann mal das Feld des Ausprobierens, denn es sollte hier nur um die Installation als solche gehen. Ich selbst befinde mich da derzeit auch in der Findungsphase, denn bislang bin ich tatsächlich gut mit einem System aus Ordnern und OCR auf der Festplatte hingekommen. paperless-ng ist da wesentlich mächtiger, wenn ihr euch da mal reinfummeln wollt. Und wer da nicht fündig wird, findet sicherlich noch jede Menge anderer DMS zum Ausprobieren. Ansonsten nehmen wir auch gerne Kommentare zu Open Source und Freeware entgegen.
| # | Vorschau | Produkt | Preis | |
|---|---|---|---|---|
| 1 |

|
Synology DS223J 2 Bay Desktop NAS, weiß |
186,90 EUR |
Bei Amazon ansehen |
| 2 |

|
Synology Diskstation DS124 NAS System |
148,90 EUR |
Bei Amazon ansehen |
| 3 |

|
Synology DS223 2-Bay Diskstation NAS (Realtek RTD1619B Quad-Core 2GB Ram 1xRJ-45 1GbE LAN-Port),... |
260,00 EUR |
Bei Amazon ansehen |
Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Habe ebenfalls die Tage ein paar DMS ausprobiert, paperless-ng hat mir da auf den ersten Blick am besten gefallen, v.a. weil ich hier die PDFs im Original aus der Ordnerstruktur sichern kann und keine DB im Hintergrund läuft.
Papermerge wäre noch ein Tipp, da war mir persönlich die Bedienung etwas zu umständlich. Dafür lassen sich hier im DMS Ordner anlegen und es muss nicht alles getaggt werden.
Ecodms benötigt die Client-Software und ist deshalb bei mir durchgefallen. Wen das nicht so stört wie mich, kann hier schnell glücklich werden.
Habe das alles durch. Letztendlich bleibe ich bei PDFs und Co. lieber „plain“. Speichere alle Dateien nach dem Schema YYYY-MM-DD_Firma_Thema_Schlagwörter
Und sortiere dies recht einfach gehalten in eine flache Ordnerstruktur.
Unter Windows wird im Datei-Explorer Vorschaufunktion für PDF genutzt und zur Suche nutze ich „Everything“ von voidtools.
Suche dann z. B. nach 2021-07*Rechnung* und bekomme dann alle Rechnungen aus dem Juli 2021 angezeigt.
Gespeichert habe ich es zentral auf einem eigenen Server und verteile die Inhalte mit nextcloud.
Geht aber natürlich auch anders 😉
Ich habe mich mittlerweile auch auf PDFs festgelegt. Lassen sich einfach erstellen, sind durchsuchbar und sind ein Dateistandard, den ich vermutlich noch Jahrzehnte auslesen und nutzen kann. Speichere (drucke) Artikel, Rezepte, Rechnungen & Co. per PDF – egal ob am PC oder Smartphone. Die werden dann je nach Zweck lokal oder in der Cloud gespeichert und sind mit den „normalen“ Bordmitteln auffindbar.
Ich bin aktuell auch auf der Suche nach einem DMS für privat. Die OCR, meist tesseract, bringt leider sehr bescheidene Ergebnisse. Gibt es ein DMS,. Welches sich mit Google Vision OCR betreiben lässt? Via API sind 1000 Scans um Monat frei. Dass würde mir dauerhaft ausreichen.
Bin ich 100%ig bei dir. Genau aus den selben Gründen und habe auch dasselbe durch wie du und bin beim selben Fazit gelandet (sogar mit identischem Namensschema) :-D.
Bei der doch überschaubaren Dokumentenmenge, die man als Angestellter ohne Selbstständigkeit so bekommt fahre ich mit dieser Taktik auf jeden Fall deutlich besser als mit so einem Dokumentenmanagement system. Grade auch was Zukunftssicherheit angeht.
Du, nutze ich bisher auch so. So viel fällt auch als Selbständiger nicht an, kommt immer drauf an 🙂
Zukunftssicherheit ist für ein DMS meiner Meinung nach der zentrale Punkt. Bei Aufbewahrungsfristen von bis zu 10 Jahren, muss man sich darauf verlassen könnne, dass das System lange funktioniert. Proprietäre Lösungen finde ich hier sehr problematisch, auch wenn ich im Einzelnen die Vorteile (schneller Index, umfangreiche Funktione) sehe.
In Bezug auf Zukunftssicherheit und PDF-Basis hat mir Office-n-PDF ganz gut gefallen. Das weiter oben erwähnte ecoDMS wäre auch nett (Multi-Plattform, erweiterbar), aber auf die Frage nach einem umfassenden Export-Konzept für die Zukunftsfähigkeit habe ich vom Support noch nicht einmal eine Antwort bekommen. Und im Handbuch war nichts dazu zu finden. Mit dieser Haltung sind leider die meisten DMS unterwegs.
Daher scheint mit PDF bzw. PDF/A immer noch die beste Basis für ein langfristiges System zu sein. Vor allem wenn man sich die Option zum Wechsel des OS offen halten will. Ein guter Index bzw. eine leistungsfähige Suche braucht man aber unbedingt dazu.
Ich habe mir paperless-ng angeschaut und du kannst das so konfigurieren. Da paperless-ng die Dokumente im Original in deinem NAS speichert, gibt es zunächst kein Problem, dass was in einem BLOB versenkt ist. Alle Dokumente können vom file system gelesen werden. Du kannst paperless auch so konfigurieren, dass du umfangreiche Namenspattern (auch für Ordnerstrukturen) konfigurieren kannst.
Doku dazu: https://paperless-ng.readthedocs.io/en/latest/advanced_usage.html#file-name-handling
Es ist schade, dass das Projekt gerade nicht unter aktiver Unterstützung ist, aber genau diese Art der Speicherung der Dokumente macht es für mich zu einem guten DSM. Denn wenn wirklich mal was hinüber ist im Index, habe ich immer noch die Dokumente.
Meine Synonogy lasse ich nurnoch als Datenspeicher laufen. Ist zu Leistungsschwach. Docker läuft auf meinem Proxmox / Docker Server. Die Dolumente Speichere ich per NFS auf meiner Synology. Vorteil, die Synology kann so in denn Stromsparmodus zudem ist die Datensicherung unabhängig von Paperless.
PaperlessNG kann ich empfehlen 🙂
Das größte Problem bei einer solchen Dokumentenverwaltung sehe ich in der langfristigen Nutzbarkeit. Was, wenn der Hauptentwickler das Projekt eingestellt? Ist die Community groß genug, zu übernehmen? Wenn nicht, kann ich die Datenbank in ein anderes Projekt/Doc-Verwaltung übernehmen?
Und auch wichtig: Lässt sich die Datenbank nach extern sichern und von extern wieder einlesen? Oder nur komplett als Docker-Container bzw. nur über die Sonos-Datenbank? Da habe ich schon schlechte Erfahrungen mit anderen Anwendungen gemacht…
Lies doch nochmal den Text, dort wird nahezu alles beantwortet.
Vielen Dank für diesen ausführlichen Bericht!
Projekt scheint vom ursprünglichen Autor nicht weiter gepflegt zu werden wie man hier aus der Diskussion entnehmen kann: https://github.com/jonaswinkler/paperless-ng/issues/1599
Das habe ich auch gerade gelesen. Ich würde ungern meine komplette Dokumentenverwaltung auf eine Lösung umstellen, die nicht mehr gepflegt wird.
Genau das ist der Grund warum ich mich für ecodms entschieden habe. Fand paperless ng wirklich überzeugend und bedienungstechnisch ecodms überlegen. Ist halt blöd wenn man 500 papierdokumente eingescannt und geshreddert hat und dann möglicherweise das archiv streikt und man ohne support dasteht.
Dito. Und ich bin mit ecodms außerordentlich zufrieden, das läuft auf einem mittelmäßig ausgestatteten Intel NUC hervorragend, Docker Instanzen auf QNAPs hab ich aber auch schon eingerichtet, das ist jedoch dann teilweise beim Updaten im Vergleich zu einer Installation auf einem Ubuntu Server relativ stressig.
Aber was macht ihr, wenn die Firma den Dienst einstellt? Bei Aufbewahrungsfristen von bis zu 10 Jahren kann auch die ecoDMS GmbH die Grätsche machen. Und dann steht ihr mit einem proprietären, datenbank-basierten System da. Bisher scheint eine Exit-Strategie nicht zu ihrer Planung zu gehören. Auf eine entsprechende Anfrage bekam ich nicht einmal eine Antwort – obwohl ich nicht als Privatperson angefragt habe, sondern im Auftrag mehrerer Kunden. DAs hat mich dann ziemlich abgeschreckt. Ein Einzel-Export von Dokumenten ist keine Lösung. Vor allem nicht, wenn man dabei alle Tags verliert.
Vom Feature-Set und der Plattform-Unabhängigkeit her gefällt mir die ecoDMS-Familien schon. Aber ohne Komplettexport ist das nicht zukunftssicher.
Bei Paperless NG liegt jedes Dokument im Orginal und nochmal separat die von Paperless NG angepasste Version im Dateisystem als stinknormale Datei (z.B. PDF) und du kannst siejedeszeit kopieren und in ein anderes Tool importieren, selbst wenn die Paperless NG Software keinen Mucks mehr macht … nur die Metadaten könnten dann verloren gehen. Das ist dann zwar auch ein Haufen Arbeit die wieder zu pflegen, aber es ist nichts verloren. Bin gerade selber dabei eine Paperless NG Instanz zu füllen, sind nun schon an die 3000 Dokumente geschafft ..
Und wenn man das automatische tagging verwendet (und sich die Konfig einfach mal per Backup sichert), kann man sich nach einem neuen Aufsetzen einen paperless-ng zumindest die regelbasierten tags einfach wieder herstellen. Aber grundsätzlich sollte man sowieso Backups machen…
Warum hast du nicht das usprüngliche Image von Jonas Winkler genommen, sondern den Fork?
Wenn ich das richtig verstanden habe, dann hat Jonas Winkler einen Fork von „paperless“ erstellt, den er „paperless-ng“ genannt hat, d.h. der Fork ist das ursprüngliche Image von Jonas Winkler.
Ein schöner Artikel, gerne öfter mal sowas in der Richtung 🙂
Das werde ich in den nächsten Tagen einmal ausprobieren, danke für den Trigger.
Die Gruppen- und Nutzer-ID kann man auch mit dem Aufgabenplaner rausfinden:
Neue Aufgabe, Benutzer auswählen und als Befehl:
id > /volume1/docker/id.txt
Dies erstellt im Docker-Ordner eine Text-Datei mit PUID und PGID als Inhalt.
Man sollte vielleicht noch darauf hinweisen dass die Zukunft des Projektes aktuell sehr ungewiss ist.
Es gibt zahlreiche Fragen nach Jonas Verbleib auf GitHub, dieser ist seit Monaten nicht mehr zu erreichen.
Aktuell überlegt sich eine Gruppe das Projekt zu forken und in einer eignen GitHub Organisation fortzuführen.
Siehe: https://github.com/jonaswinkler/paperless-ng/issues/1599
https://github.com/eikek/docspell
Habe ich noch nicht selber ausprobiert, aber werde ich demnächst machen!
Sieht von den Screenshots sehr interessant aus.
Sieht vielversprend aus…
Sieht nicht mehr vielversprechend aus, wenn man die Github Insights anschaut… Das übliche Problem vieler Projekte: zu wenig Manpower. Es gibt nur zwei Hauptentwickler, der Rest trägt fast nichts bei. Das ist bei einem DMS das langzeitstabil sein muss ein Problem (siehe z.B. die Kommentare zur Situation bei paperless-ng und viele andere Projekte).
Vor einer Software-Entscheidung ist für mich daher immer der Blick in die Insights Pflicht. Ich habe schon zu viele Projekte sterben sehen. Und wenn dann mein digitales Archiv dran hängt, ist das mehr als blöd.
Ich verwende für sowas Obsidian.md. Ich lasse mir mit ABBYY im Hintergrund nach der OCR-Erkennung nicht nur durchsuchbare PDFs erzeugen, sondern lasse den erkannten Text in Textdateien schreiben. Ein Skript trägt mir einen Wiki-Link zur PDF in die Textdaten ein, bei nachträglicher Umbenennung in *.md.
In einem Vault für Dokumente kann ich in den Markdowndateien nun ganz einfach verschlagworten, indem ich vor relvante Worte einfach ein „#“ schreibe. Und somit habe ich einen Tag.
Das ganze lasse ich dann auf mein Handy synchronisieren und habe alle Dokumente auch auf meinem Handy. Und nicht nur per normaler Suche alles schnell auffindbar, sondern auch per Tags. Eine Ordnerstruktur braucht man so eigentlich nicht.
Und mit Markdown bin ich für immer unabhängig. Aber mit Obsidian habe ich maximalen Luxus.
Ist Abby nicht kostenpflichtig?
Ja.
Das liest sich sehr interessant. Kannst Du da vllt. etwas mehr Details bereitstellen?
Hallo Tobi,
ich nutze dafür ABBY Hotfolder als Bestandteil von ABBYY FineReader 12 Corporate. Sollte man noch irgendwo günstig bekommen. Hier kann man mehrere Ausgaben bestimmen. U.a. PDF/A aber eben auch Text. Und der steht dort sogar leicht formatiert. Mit Absätzen und Umbrüchen. Also relativ übersichtlich.
Kennst du Obsidian? Hier werden Worte mit „#“ ganz simpel direkt als Tag angelegt. Und von Haus aus kann Obsidian sehr gut mit Tags umgehen. Es gibt aber auch noch reichlich PlugIns, die das noch komfortabler machen. Und wenn du deine Dokumente untereinander verlinkst, bekommst du auch noch eine spektakuläre grafische Ansicht. Und sind1 wir mal ehrlich, wenn wir ein Dokument suchen, interessiert uns der Inhalt. Da reicht eine Text-, respektive Markdown-Datei. Und in dieser könntest du dann auch noch kommentieren und hervorheben.
Mit einem PHP-Skript gehe ich rekursiv durch alle Pfade in die erkannte PDFs und TXTs abgelegt wurden und erstelle die „Sidekick“-Textdatei. Das ist in jeder Skriptsprache eine simple Aufgabe. Also auch in Python oder Perl sind das wenige Zeilen Code. Ein Wiki-Link zur Original-PDF sieht dann so aus: [[Originaldateiname.pdf]] Und in Obsidisan ist es dann auch völlig egal, in welchem Ordner die Datei ist, selbst wenn du sie versehentlich woanders hinverschiebst. Das Umbenennen in *.md nicht vergessen. Es bleibt natürlich eine Textdatei.
Und der Vault in Obsidian bleibt ein normaler Ordner mit Textdateien und PDFs im Dateisystem. Also mit dem anderen PDF-Viewer, Markdown-Editor oder Notepad einzusehen. Und auch die systemweite Suche (Windowssuche) funktioniert natürlich. Eine Datensicherung per Cloud oder Obsidian-Sync ergibt sich dann ganz „automatisch“.
Wenn man mobil darauf zugreifen will, funktioniert es mit Obsidian-Sync am besten.
Ich komme übrigens von Office-N-PDF. Extrem langsame Weiterentwicklung und haarsträubende Auslegung der Lizenzbedingungen haben mich von dieser mir unsympathischen Firma abwandern lassen. Aber das ist eine andere Geschichte….
Hi,
danke für die Ausführung. Obsidian kenne ich bisher nicht. Werde ich mir aber dann mal anschauen. Aktuell habe ich uch pdf/a mit abby kreiert und die liegen halt auf meiner syn.
Das geht schon alles, ganz ok, aber es geht wie du zeigst halt auch besser 😉
Danke für diesen Tipp. Den werde ich ausprobieren. Sinnvoll ist sicherlich auch die Durchsubarkeit von Word&Co Dokumenten. In der Anleitung steht etwas von Tika. In der Doku: „If you wish to use this, you must provide a Tika server and a Gotenberg server, configure their endpoints, and enable the feature.“
Muss auf dem Synology Docker noch etwas dafür aufgesetzt werden?
VG
Hi!
Ja, du benötigst Tika und Gotenberg. Allerdings ganz bestimmte Versionen, nicht latest nehmen.
apache/tika:1.27
thecodingmachine/gotenberg:6.0.4
Lade dir beide Images mit Docker in deinem Synology herunter. Starte diese und gib unter erweiterten Einstellungen an, dass die Container immer neu gestartet werden sollen und zur Sicherheit änderst du den „automatischen Port“ auf 9998 für Tika und 3000 für Gotenberg.
Dann musst du paperless-ng stoppen, dann kannst du die Umgebungsvariablen bearbeiten. Aktiviere Tika Unterstützung, wie in https://paperless-ng.readthedocs.io/en/latest/configuration.html#tika-settings angegeben. Die URLs musst du evtl. gar nicht definieren. Also nur PAPERLESS_TIKA_ENABLED=1 setzen.
Dann paperless-ng wieder starten, anmelden und in der Startseite ein Word Dokument per Drag&Drop hinzufügen. Wenn das „Grün“ durchläuft, alles ok. Wenn „rot“, dann hast du entweder eine falsche Gotenberg/Tika Version oder paperless-ng erreicht nicht über localhost die ports. Dann musst du die URLs ggf anpassen oder du hast was mit deinem bridge-Netzwerk was falsch gemacht.
Hi,
vielleicht könntest du mir helfen?
Alles nach Anleitung gemacht.
docker-compose.env:
PAPERLESS_TIKA_ENABLE: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://localhost:3000
PAPERLESS_TIKA_ENDPOINT: http://localhost:9998
Beide Docker Pakete installiert und die Ports entsprechend gesetzt.
Feld trotzdem rot: Dateityp application/msword nicht unterstützt
Im Terminal von paperless-ng:
[2022-02-10 13:26:16,173] [WARNING] [django.request] Bad Request: /api/documents/post_document/
Hi!
Also in Synology verwende ich keine .env Datei, die Parameter setze ich in der Compose Datei. Siehst du die ENV Parameter denn im laufenden Container gesetzt? (Container -> Details – Überblick, rechts unten).
Wenn nicht, Container stoppen, Bearbeiten, Umgebungsvariablen per Hand hinzufügen.
Danke, das war schon mal einfacher, so die Variablen zu setzen. Das habe ich jetzt gemacht. Trotzdem leider:
[2022-02-10 15:28:37,411] [WARNING] [paperless.management.consumer] Not consuming file /data/consume/Vereinbarung.docx: Unknown file extension.
Hast du evtl. noch eine Idee, wo der Fehler liegen könnte? Danke.
Meh!
Statt
PAPERLESS_TIKA_ENABLED=
hatte ich Dummerchen
PAPERLESS_TIKA_ENABLE=
Nächstes Mal lieber direkt ICH=doof
Jetzt scheitert es immer noch daran, dass paperless den laufenden Tika Server nicht kontaktieren kann. Ich robbe mich ran …. 😉
Ich mache mal weiter mit meiner Fehlersuche. Ich habe jetzt die TIKA und gotenberg Container umbenannt in tika und gotenberg und die Variablen von paperless-ng entsprechend auf gotenberg:3000 und tika:9998 gesetzt.
Jetzt verschluckt sich aber Tika an einer einfachen Word Datei:
Could not parse /tmp/paperless/paperles
s-upload-n8dl6z7x with tika server at tika:9998: No connection adapters were found for ‚://None:80/rmeta/text‘
Namen der Container geht nur, wenn sie im selben Docker Netzwerk sind. Nutzt du für die Container nur bridge (was man eigentlich nicht mehr machen sollte), hast du keine Namensauflösung. Dann bleibt es bei localhost:port.
Hallo,
ich verzweifele noch daran… Paperless läuft nach der Anleitung oben. tika und gotenberg mit den entsprechenden Versionen in jeweiligen Containern in Host-Modus. Dennoch kann paperless tika nicht starten.
Im log von tika steht dass die IP Adresse http:0.0.0.0:9998 ist. Ob das ein Fehler sein könnte?
Hallo zusammen, ich habe still mitgelesen und werfe hier einen Wordaround ein, der mit geholfen hat:
https://github.com/jonaswinkler/paperless-ng/issues/1594
As workaround you can use this
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://paperless-gotenberg:3000/forms/libreoffice/convert#
Hallo Josch,
vielen Dank für die hilfreichen Tipps.
Am Anfang hat es auf meinem Synology-NAS nicht funktioniert.
Mit den beschrieben Versionen:
apache/tika:1.27
thecodingmachine/gotenberg:6.0.4 hat es funktioniert !
Ich habe folgendes gemacht
Setzen folgender Variablen im paperless-ng Container:
PAPERLESS_TIKA_ENDPOINT: http://IP des Synology NAS:9998
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://IP des Synology NAS:3000
PAPERLESS_TIKA_ENABLED: 1
Wichtig dabei (TIKA und Gotenberg Container sind im gleichen Netz wie der Docker Host (nicht bridged).
Hope it helps!
Thorsten
Hallo!
Danke für Deine Ausführung. Ich habe die beiden Docker-Container und die Unterstützung für Tika in paperless-ng einegtragen. Die URLS habe ich als localhost und mit jew. Port auc eingetragen.
Wenn ich eine Word Datei per Drag und Drop übergebe, kommt die Fehlermeldung, dass er sich mit Tika nicht verbinden kann.
Mein Paperless-ng ist nach der Anleitung oben aufgesetzt. Läuft also im Bridge Modus. Die beiden anderen Docker sind nun im Host Modus. Klappt leider so nicht. Hast Du einen Rat für mich?
VG vsa
Die Anleitung ist gut, aber man auch mittels des Texteditors der Syno eine docker-compose.yml erstellen und in ein Unterverzeichnis des docker Ordners packen. Den obigen Befehl kann man super mittels der Seite composerize.com umwandeln. Ideal um später ggf auf andere Plattformen zu portieren. Auf der Syno muss man dann nur noch in das Verzeichnis wechseln und dann einfach starten mittels „docker-compose up -d“
Wäre mein Vorschlag ich mit SSH eh auf die Syno muss.
Moin zusammen.
Kennt in diesem Zusammenhang jemand einen PDF Drucker, der die Datei möglichst klein bekommt? Da gibt es ja große Unterschiede. Selbst wenn ich eine Mail drucken will, nur Text, eine Drittel DIN A4 Seite komme ich auf <60kb.
PDFCreator (von http://www.pdfforge.org).
Der Artikel kommt gerade zu einer Zeit wo ich meine Dokumente vor ein paar Wochen komplett auf Paperless-ng umgestellt habe.
Über 10 Jahre habe ich meine alles als PDF in Ordnerstrukturen abgelegt.
Das ist gut aber die Durchsuchbarkeit in Paperless-ng hat doch einige Vorteile.
Ich kann nur empfehlen sich auf der Console per ssh anzumelden einen Ordner anzulegen und die Konfig über yml Dateien zu machen.
Alles andere ist nur herumgewürge.
Mein Paperpless-ng läuft mit mir auf einer Qnap Nas.
Ihr braucht nur 2 Befehle:
docker-compose pull
docker-compose up -d
In den Kommentaren habe ich gelesen das es bedenken gibt. Was passiert wenn das Projekt nicht weitergeführt wird.
Paperless-ng legt alle Dokumente 2Mal ab 1 Mal auch im Original im den Archiv Ordnern.
Unnd das in dem Format den ihr in der yml Datei vorgegeben habt.
Bei mir so:
PAPERLESS_FILENAME_FORMAT={document_type}/{correspondent}/{created_year}_{created_month}_{created_day}_{asn}_{title}_{tag_list}
In der Paperless-ng Hilfe wird alles sehr gut beschrieben.
Wer das jetzt schon in einer Flachen Struktur abgelegt hat wird das mit den Einstellungen möglicher weise 1:1 ablegen können und seine PDF auch ohne Paperless weiternutzen können sollte er mit der Software einmal unzufrieden sein oder das Projekt eingestellt wird.
Hallo Sven,
ich verzweifle bei der Einrichtung des Docker Containers auf meiner QNAP.
Könntest du bitte erklären, wie ich das ganze installiert bekomme?
Danke im Voraus.
Hallo Marko ja klar.
Per SSH auf die Qnap.
Anschließend
cd /share/container/
Kann sein das der Ordner bei dir anders heißt.
Anschließend mkdir paperless-ng
cd /paperless-ng
anschließend diese 3 Dateien aus dem Link in den Ordner kopieren
https://schicks.digital/download/e804d72f-2d23-4552-80a8-1271da552a74#EqzkShoNEqNnAUxLBao1h8qE57Fyv1AjKC0Ufv48w%2Fc%3D
Bitte die 4 Pfade in der yml Datei anpassen. Dort wird die Datenbank die PDF Dateien abgelegt.
Der 4. Eintrag ist für den Consume Ordner.
Anschließend
Im Verzeichnis paperless-ng
docker-compose pull
docker-ompose up -d
Jetzt noch
sudo docker exec -it paperless_webserver_1 /bin/bash
und den Admin Benutzer mit
python3 manage.py createsuperuser
anlegen.
Jetzt kannst du Paperless im Webbroser nutzen.
Vielen Dank!
Vielen Dank. Die Installation hat auch geklappt, leider lässt sich die Anwendung in der Container-Station nach einem Reboot nicht starten (Automatisch wäre noch schöner). Kannst du da auch noch weiterhelfen?
Wäre über eine Anleitung für QNAP auch sehr dankbar! 🙂
Die Anleitung von svenp funktioniert auf der QNAP eigentlich sehr gut. Kann man 1:1 so umsetzen.
Allerdings muss man in der „docker-compose.yml“ die Version der „postgres“ Komponente von 13 auf die ältere Version 11 ändern. Die veraltete Docker Version auf der QNAP kommt mit der Version 13 nicht zurecht.
image: postgres:13 –> image: postgres:11
Alle die ihre Dokumente digital aufbewahren wollen sollten alles verwenden, nur keine Bastellösung wie dieser Docker Müll hier!
Habe auch noch keine echte DMS gesehen die mir gefallen hat, zumindest nicht ohne viel Geld in die Hand zu nehmen, aber dann lasse ich es lieber anstatt sowas hier zu verwenden was mehr als unsicher ist!
Das einzige was hier unsicher ist, auf solche Kommentare wie diesen zu hören. Die Dateien werden alle wie sie sind im Ordnerverzeichnis abgelegt (Original und modifiziert) Das DMS wird nur übergestülpt. Außerdem ist Docker ne feine Sache
Zu de_DE.UTF-8: Warum nicht gleich?:
docker run -d –name=paperless-ng \
-p 8931:8000 \
-e PUID=1026 \
-e PGID=100 \
-e LANGUAGE=de_DE.UTF-8 \
-e LANG=de_DE.UTF-8 \
-e TZ=Europe/Berlin \
-v /volume1/docker/paperless/config:/config \
-v /volume1/docker/paperless/data:/data \
–restart always \
ghcr.io/linuxserver/paperless-ng
@Frank
da fehlen ein paar „-“ an den entscheidenden Stellen, so sollte es aber passen:
docker run -d –name=paperless-ng \
-p 8931:8000 \
-e PUID=1026 \
-e PGID=100 \
-e LANGUAGE=de_DE.UTF-8 \
-e LANG=de_DE.UTF-8 \
-e TZ=Europe/Berlin \
-v /volume1/docker/paperless/config:/config \
-v /volume1/docker/paperless/data:/data \
–restart always \
ghcr.io/linuxserver/paperless-ng
Ganz wichtig finde ich persönlich den Eintrag
PAPERLESS_FILENAME_FORMAT={created_year}/{correspondent}/{title}
der im Docker mit gesetzt werden sollte, damit man auch eine vernünftige Struktur in der Ablage erhält und die PDF Dateien nicht einfach nach dem Format 0000001.pdf abgelegt werden. Wenn das so Flat abgelegt wird hat man kaum eine Chance da noch etwas vernünftig zu finden.
Daher unbedingt die Parameter ansehen: https://paperless-ng.readthedocs.io/en/latest/advanced_usage.html#file-name-handling
Im Nachhinein etwas zu ändern ist immer umständlich
unglaublich, was mach die Forensoftware hier. verändert doch einfach den Text aus „- Leerzeichen -“ wird ein „-„. Das ist übel für den Sourcecode. Vor diese beiden Parammeter sollte ein doppeltes „-“ ohne Leerzeichen dazwischen:
– – name=paperless-ng \
– – restart always \
Danke Caschy für die Anleitung. Nutze das schon seit einem Jahr und habe schon 10 Ordner gegen 1 tauschen können. Danke für die Werbung für dieses Projekt !