Lumiere: Realistische Videos durch generative KI
![]() von caschy | 3 Kommentare
von caschy | 3 Kommentare
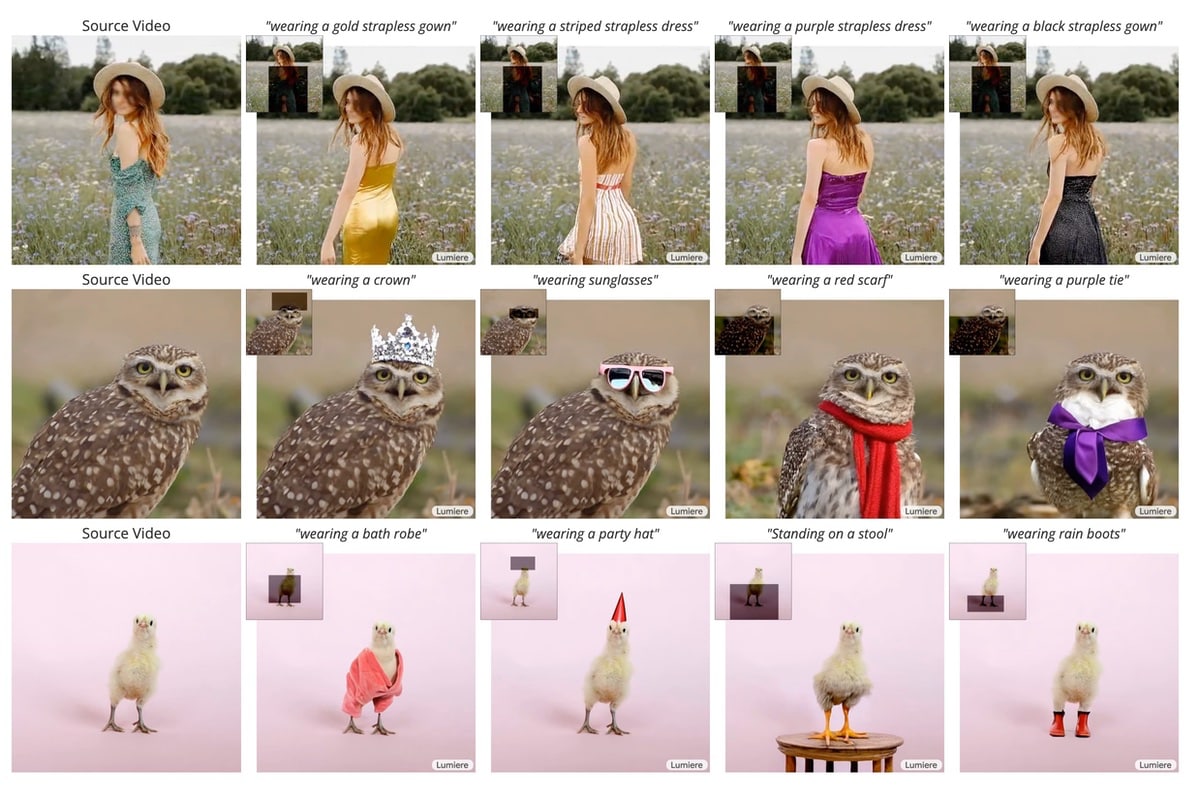
Googles Forscher haben in Zusammenarbeit mit Technion, der Tel-Aviv University und dem Weizmann Institute etwas Interessantes gezeigt. Man nennt das Ganze Lumiere und dabei handelt es sich um ein Text-to-Vide-Diffusionsmodell. Vermutlich kennen es viele durch Midjourney oder auch ChatGP: Man wirft Text rein und bekommt ein Bild raus. Seit längerem gibt es das auch für Videosequenzen. Lumiere nutzt neue Architekturen und Algorithmen, um das Ganze auf ein neues Level zu hieven.
Neben Text-to-Video beherrscht Lumiere auch Image-to-Video und Stylized Generation. Schaut man sich die Demovideos auf der Webseite an, dann wird man erkennen, dass das schon ganz großes KI-Kino ist. Zur Realisierung führte man eine „Space-Time U-Net-Architektur“ ein, die die gesamte Dauer des Videos auf einmal generiert. Dies steht im Gegensatz zu bestehenden Video-Modellen, die entfernte Keyframes synthetisieren, gefolgt von einer zeitlichen Super-Auflösung – ein Ansatz, der es schwierig macht, eine globale zeitliche Konsistenz zu erreichen, so die Forscher.
Nett anzuschauen, doch ein Makel bleibt: Es ist ein Forschungsprojekt, weder ihr noch ich können sich irgendwo einloggen, um solche Kunstwerke zu erstellen.

- Vielseitiges 2-in-1-Ladedesign: Die Schnellladegerät mit USB-C- und USB-A-Anschlüssen, mit denen Sie...
Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Beeindruckend!
Da sieht aber noch sehr Vieles vollkommen daneben aus. Anscheined ein großes Problem, dass Bewegungen auf verschiedenen Ebenen teils überhaupt nicht zusammenpassen. Deshalb hat man hier wohl auch bewusst Beispiele mit möglichst wenigen Bewegungsebenen gewählt.
Und über das „Winking-Girl“, welches eher ein Gesicht eines Aliens aufweist, braucht man schon gar nicht zu reden.
Auch dies ist wieder ein Beispiel für das Dilemma der derzeitigen KI: Es scheint zwar zu funktionieren, aber eben nur bis zu einem gewissen Grad wie bspw. 80%. Aber wie beim autonomen Fahren oder auch LLMs wie ChatGPT & Co. bekommt man die letzten % nicht in den Griff.
Ob man diese letzten % jemals vernünftig in den Griff bekommt steht meiner Meinung nach in den Sternen. Es wie bei LLMs manuell durch „KI-Flüsterer“ zu schaffen, ist meiner Meinung kein erfolgversprechender Weg, da dieser Aufwand permanent zu treiben wäre und dieser zu groß ist.
Das „Winking-Girl“ ist von Vermeer und muss so aussehen.
https://de.m.wikipedia.org/wiki/Das_M%C3%A4dchen_mit_dem_Perlenohrgeh%C3%A4nge