Mistral stellt Small 3.1 vor: Das leistungsstärkste KI-Modell seiner Klasse
![]() von Olli | 3 Kommentare
von Olli | 3 Kommentare
Mistral hat Small 3.1 vorgestellt, ein unter Apache 2.0 lizenziertes KI-Modell, das die Konkurrenz in seiner Gewichtsklasse angeblich übertreffen soll. Das Modell besitzt 24 Milliarden Parameter und möchte mit verbesserten Text- und Multimodal-Fähigkeiten sowie einem erweiterten Kontextfenster von 128k Token überzeugen.
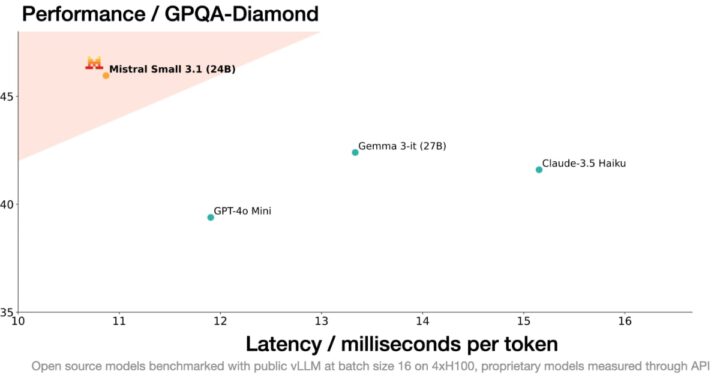
Das sind die Leistungsmerkmale im Überblick
- Übertrifft vergleichbare Modelle wie Gemma 3 und GPT-4o Mini
- 150 Token pro Sekunde Inferenzgeschwindigkeit
- Läuft auf einzelner RTX 4090 oder Mac mit 32GB RAM
- Unterstützt mehrere Sprachen und Multimodal-Eingaben
- Geeignet für Function Calling und Conversational AI
Das Modell ist ab sofort über Hugging Face verfügbar und wird in den kommenden Wochen auch auf NVIDIA NIM und Microsoft Azure AI Foundry erscheinen. Für Unternehmensanwendungen bietet Mistral eine optimierte Inferenz-Infrastruktur an.
Die Benchmarks findet ihr direkt bei Mistral. Diese zeigen durchweg überlegene Leistung in Bereichen wie Textverständnis, multimodales Lernen und Verarbeitung langer Kontexte. Nicht schlecht, was das französische Unternehmen in der letzten Zeit so auf die Beine stellt.



Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
> Läuft auf einzelner RTX 4090 oder Mac mit 32GB RAM
Nicht ganz.
Ich habe mich gestern auch – zu früh – gefreut:
> Note: Running Mistral-Small-3.1-24B-Instruct-2503 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
Das volle Modell braucht 55 GB RAM.
> Mistral Small 3.1 can be deployed locally and is exceptionally „knowledge-dense,“ fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized.
Um auf 32 GB laufen zu können, muss sie quantisiert werden, damit wird die Genauigkeit reduziert.
Schade! Wird wohl noch eine Zeit dauern, bis sich die Lücke für die Offlineanwendung schließt.
Aber nicht mehr lange – find es erstaunlich wie schnell wir von einer „nur online in der 100Mrd-Cloud ausführbar“, zu „läuft daheim auf dem Rechner in der vollen Variante“ gekommen sind (etwas überspitzt ausgedrückt).
Kann es mir gerade nicht auszumalen wo wir in 1-2 Jahren sind.