Mistral veröffentlicht sein Mistral Large 2 LLM
![]() von Mike Leitner | 5 Kommentare
von Mike Leitner | 5 Kommentare
Quelle: Mistral
Schlag auf Schlag geht es weiter bei den LLMs und nach Llama 3.1 folgt Mistral mit seinem Modell Mistral Large 2(2407). Es hat eine Kontextgröße von 128.000 und 123 Milliarden Parameter. Es soll effizient und schnell sein, ist aber mit ca. 5 €/Million Token nicht billig. Mistral zeigt in seinem Blogbeitrag auch Benchmarks und offenbart einige interessante Aspekte, wie die Mehrsprachigkeit und die Fähigkeit, Anweisungen zu folgen. In beiden Bereichen schneidet Mistral Large 2 gut ab und kommt an GPT-4o oder Claude 3.5 Sonnet heran.
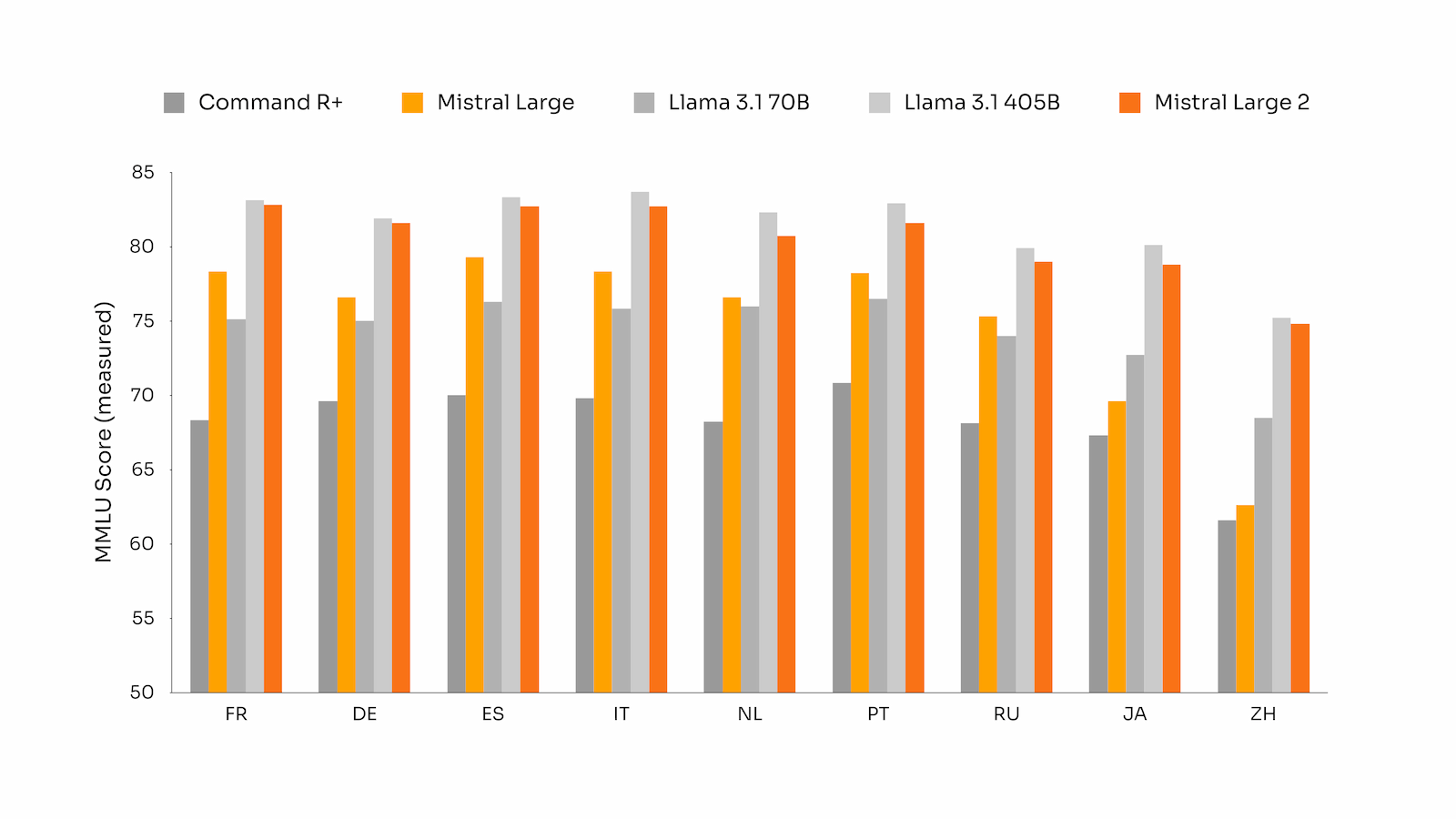
Quelle: Mistral
Besonderer Wert soll auf die Vermeidung von „Halluzinationen“ gelegt worden sein. Das Modell soll sogar darauf trainiert worden sein, vorsichtig und genau zu antworten und gegebenenfalls zuzugeben, wenn es eine Frage nicht beantworten kann.
Quelle: Mistral
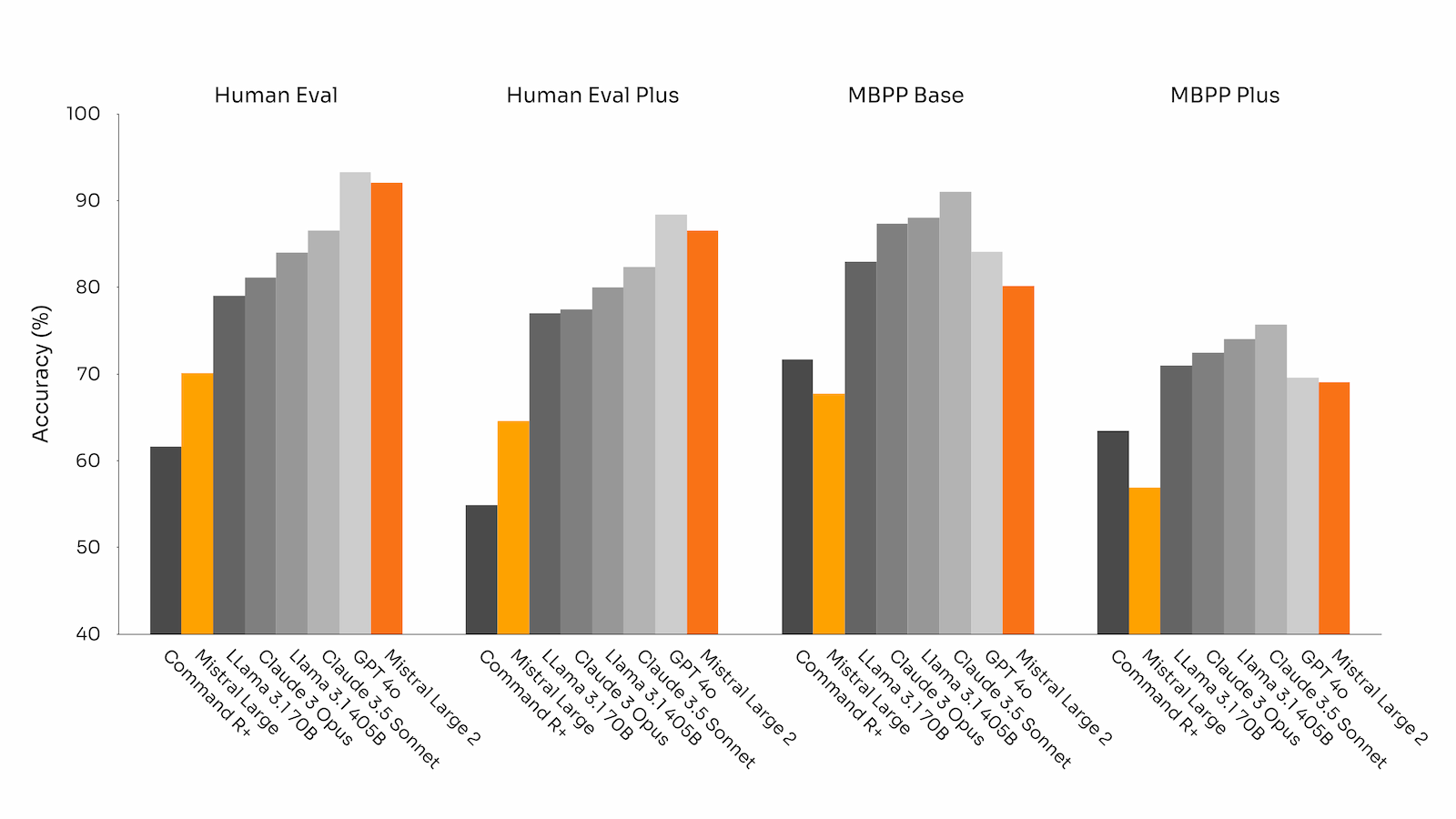
Auch dieses Modell habe ich kurz getestet und muss sagen, dass es sich teilweise besser schlägt als Llama 3.1-405B. Eine Schwäche der Llama-Modelle zeigt sich hier besonders, sie sind nicht besonders gut im Folgen von Anweisungen. Dafür ist Large-2 aber auch nicht so gut im Reasoning und hat bei meinen Tests auch einfach Dinge übersetzt, die nicht übersetzt werden sollten (Funktion in TypeScript). Im Moment ist aber Claude 3.5 Sonnet mein Favorit, es ist einfach zuverlässig in der Ausgabe und vergleichsweise günstig. Was ist euer Favorit?



Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Ich teste immer das Modell, von dem ich denke, dass es mir am meisten nützen könnte. Am liebsten jedoch Claude Sonnet 3.5, GPT-4o und das Mini-Modell davon, wenn es schnell gehen muss und nichts kosten soll.
Ach ja, ich nutze das alles über einen Multi-LLM-Anbieter namens Straico, habe dort mal günstig eine Lifetime-Lizenz erworben. Für meine Arbeit ist das wunderbar, ständig Updates, ich kann mich nicht beklagen.
Oder einfach http://www.jan.ai als FOSS Alternative nutzen.
Derzeit habe ich keinen Favoriten und meine Spielphase ist auch vorbei.
Davon abgesehen ist die Frage wie lange das noch so weitergeht.
Denn das „nicht billig“ ist wohl nach der Meldung https://www.heise.de/news/OpenAI-drohen-Miese-in-Hoehe-von-5-Milliarden-US-Dollar-9813052.html immer noch viel zu billig.
Die AI Firmen verdienen kein Geld, sie verbrennen es massiv und der Nutzen ist immer noch kaum gegeben.
Der einzige der derzeit gut verdient ist der Verleiher der Schaufeln, also NVIDIA.
Also wird AI in Zukunft entweder massiv teurer oder geht unter.
Spätestens wenn die ersten Investoren Geld sehen wollen.
LLMs? Entschuldigung, worum geht es in diesem Artikel?
Wir haben jetzt einen ChatGPT-Zugang von unserem Arbeitgeber zum Testen bekommen, aber niemandem will etwas dienstliches einfallen…
https://www.faz.net/pro/d-economy/kuenstliche-intelligenz/generative-ki-bringt-aktuell-mehr-produktivitaet-aber-kaum-umsatzzuwachs-19874375.html
Ja, jedes Hypethema nordet sich ein.
Sei es, daß man jetzt feststellt, daß Microservices oft zu OverEngineering führen, die Cloud gerne 100-150% Mehrkosten erzeugt bei Lift&Shift, etc. pp.