ChatGPT: OpenAI ermöglicht Seitenbetreibern Deaktivierung des Web-Crawlers
![]() von Benjamin Mamerow | 7 Kommentare
von Benjamin Mamerow | 7 Kommentare

Nicht jeder Webseitenbetreiber möchte, dass die Informationen auf der eigenen Präsenz vom Crawler der KI von ChatGPT aus dem Hause OpenAI abgegriffen werden. Das Unternehmen hat hierfür nun eine Änderung implementiert, mit der sich genau dagegen widersprechen lässt. OpenAI bietet an, den Web-Crawler daran zu hindern, Informationen von der Webseite zu extrahieren, um damit die GPT-Modelle zu trainieren.
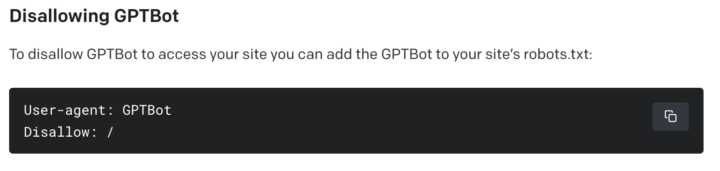
In einem Blogeintrag hat man erklärt, dass Betreiber von Webseiten entweder explizit den GPTBot-Crawler in der Robots.txt-Datei ihrer Webseite ausschließen oder dessen IP-Adresse blockieren können. Webseiten, die durch den GPTBot-Crawler indexiert wurden, könnten potenziell zur Verbesserung zukünftiger Modelle verwendet werden. Dabei werden Quellen, die Paywall-Zugang erfordern, persönlich identifizierbare Informationen (PII) sammeln oder gegen Richtlinien verstoßen, herausgefiltert. Bei Quellen, die diese Ausschlusskriterien nicht erfüllen, könnte der Zugriff des GPTBot auf die Webseite dazu beitragen, die Genauigkeit der KI-Modelle zu erhöhen und deren allgemeine Fähigkeiten sowie Sicherheit zu verbessern, heißt es hier weiter. Mal sehen, wie es damit nun zukünftig weitergehen wird. Immerhin wird es zahlreiche Autoren, Verlage und dergleichen geben, welche von der neuen Option umgehend Gebrauch machen werden.



Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Am Besten bauen alle VT/Fakenews-Blogs und Seiten mit Geschichten sowie Verlage, die Romane vertreiben dies sofort in ihren Quelltext mit ein.
Denn aktuell hält ChatGPT das alles doch durchweg für bare Münze…
gerade die bauen eher ein Allow ein. Damit die „Wahrheit“ verbreitet wird
Ich vermute eher das Gegenteil. Seriöse Seiten werden es aus Urheberrechtsgründen verwenden und damit die Ergebnisse weiter verschlechtert.
Verbieten diese Verlage eigentlich auch die Verbreitung deren Bücher an Schulen, damit Menschenkinder davon auf keinen Fall lernen können? Menschen machen auch nichts anderes: Eindrücke aufnehmen, variieren, modifizieren – nennt sich dann Kreativität – und reproduzieren. Und Menschen schwafeln genauso Blödsinn, wenn sie keine Ahnung haben.
Menschen lernen. KI sammelt nur und speichert ab, um dann fremde Inhalte abzurufen, für die andere Menschen kreativ und fleißig sein mussten. Wenn man das denn wirklich KI nennen möchte, denn so richtig ist es ja wieder einmal keine KI, sondern nur eine Art Antwortmaschine, die vorher das halbe Internet gescannt hat. Inwiefern das nun „cool“ ist, bleibt jedem selbst zu bewerten. Ich für meinen Teil finde das nicht so prall, wenn Inhalte, für die jemand arbeiten musste, um die Schlüsse zu ziehen oder die Recherchen zu sammeln, jetzt einfach so „geklaut“ werden. Nichts anderes ist das. Nur neu verpackt.
An Schulen wird aber für die Bücher bezahlt.
Jetzt können sie so etwas ja anbieten.
Das verbietet es dem Crawler nur, dass er fortan nicht mehr auf die Webeite zugreifen soll. Was bereits abgegriffen wurde, wird ChatGPT nicht vergessen.