Claude Sonnet 4.5: Anthropics neues KI-Modell vorgestellt
![]() von caschy | 8 Kommentare
von caschy | 8 Kommentare
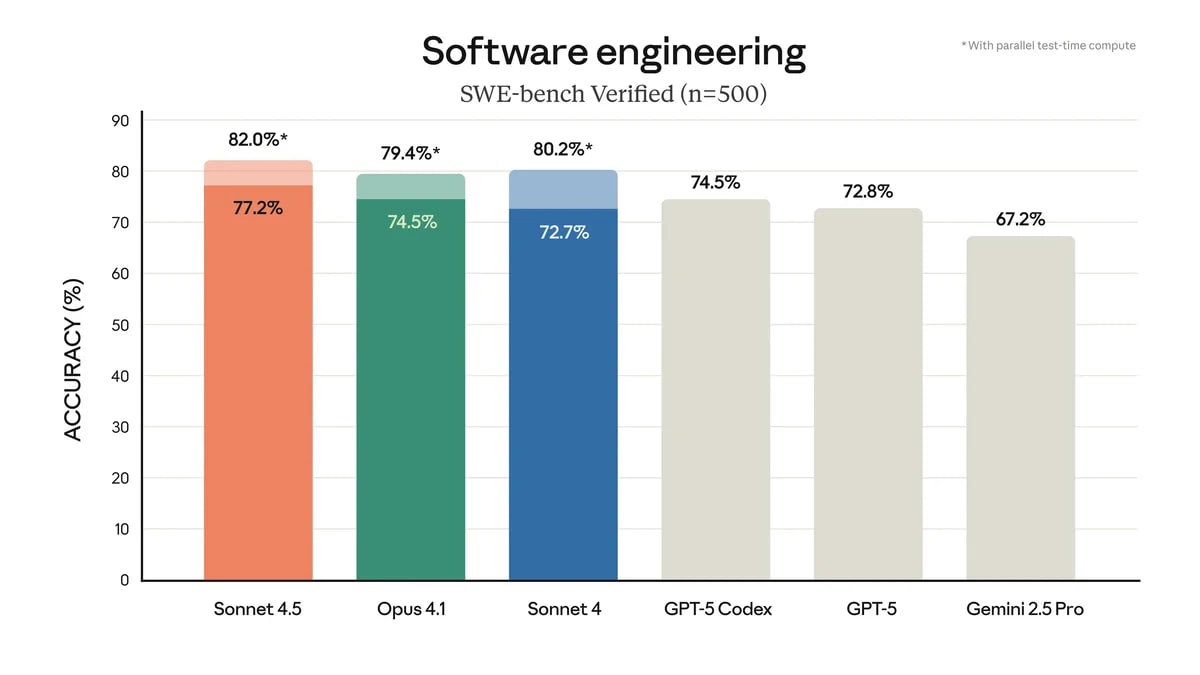
Anthropic legt nach und präsentierte heute mit Sonnet 4.5 ein KI-Modell, das in Sachen Coding neue Standards setzen soll. Erst im Mai hatte das Unternehmen Opus 4 und Sonnet 4 vorgestellt, jetzt folgt der nächste Streich. Anthropic geizt nicht mit Zahlen: Im OSWorld-Benchmark, der KI-Modelle bei realen Computeraufgaben testet, erreicht Sonnet 4.5 einen Wert von 61,4 Prozent. Damit liegt das System satte 17 Prozentpunkte vor dem teureren Opus 4.1 und lässt auch die Konkurrenz von Google (Gemini 2.5 Pro) und OpenAI (GPT-5) hinter sich. Sonnet 4.5 kann jetzt auch bis zu 30 Stunden am Stück an mehrstufigen Projekten arbeiten. Das ist eine klare Steigerung gegenüber den sieben Stunden, die Opus 4 zum Start schaffte.
Bei der Sicherheit hat Anthropic ebenfalls nachgelegt. Nach intensivem Training zeigt sich Sonnet 4.5 resistenter gegen typische KI-Schwächen wie übertriebene Gefälligkeit, Täuschungsversuche oder das Fördern von realitätsfremdem Denken. Auch gegen Prompt-Injection-Angriffe wurde das System gehärtet. Wegen der fortgeschrittenen Fähigkeiten läuft Sonnet 4.5 unter dem AI Safety Level 3 Framework, das Filter gegen potenziell gefährliche Ausgaben enthält. Wer sich da genauer einlesen möchte, klickt auf diesen Link.

- DIE WELTBESTE AKTIVE GERÄUSCHUNTERDRÜCKUNG BEI IN‑EAR KOPFHÖRERN – Reduziert bis zu 2x mehr...

- UNIBODY DESIGN. FÜR EINZIGARTIGE PERFORMANCE. − Heißgeschmiedetes Aluminium Unibody Design für das...

- WICHTIGE GESUNDHEITSFEATURES – Die Temperaturerkennung ermöglicht umfangreichere Insights in der...
Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Bin gespannt. Opus 4.1 liegt zum Beispiel bei Scripting in der Appsheet irgendwo zwischen herausragend gut und unterirdischem Versagen, wobei ab einem bestimmten Punkt der Fehlersuche du das auch aufgeben kannst, weil da nix mehr rum kommt. Dann haut es wieder bei irgendwelchen Spezialproblemen eine Toplösung nach der anderen raus, wo du ewig gebraucht hättest, um das selber zu lösen. Irgendwie läuft das alles noch nicht rund, andererseits beschleunigt das Projekte aber auch wieder enorm. Ich möchte es auch jeden Fall nicht missen, Claude KI und Gemini Pro sind in meiner Arbeit wichtige Tools geworden, hätte ich mir vor zwei Jahren nicht vorstellen können
Hast du da mal konkrete Beispiele, wie sie dir den Alltag erleichtern?
Ja, sehe ich auch so. Als Tools zur Unterstützung sind vor allem Gemini und Claude top. Meiner Meinung nach haben beide auch ChatGPT deutlich überholt.
Nur bin ich eben auch der Meinung, dass es eben nur Tools zur Unterstützung sind, quasi ein deutlich besseres Google und nicht das, als was es immer von den Firmen verkauft wird.
Und da die Modelle enorm viel an Kosten verschlingen und da auch extrem viele Investorengelder drin liegen, bin ich gespannt, ob da nicht die Bubble platzt und eine gewisse Einsicht einkehrt, dass es niemals eigenständig so produktiv werden könnte, um nur im Ansatz Energiekosten oder investiertes Geld zu rechtfertigen. Befürchte, dann werden manche Modelle ganz verschwinden oder extrem teuer.
Auf GitHub wurde der Copilot gerade so integriert, dass man per Click einfache Tasks an den Agenten delegieren kann. Macht mal VSCode zu und probiert die Agenten in der CLI.
Moin, ich verstehe das mit den 61,4% nicht.
Da bin ich mal gespannt. An einfachster Logik in einem XML Dokument ist Opus bei mir gerade kläglich gescheitert.
Bist du sicher, dass es nicht an deiner Anfrage lag? Ich habe schon vor längerer Zeit von Claude Code produzieren lassen anhand einer XML-Datei mit Daten und meinen Wünschen, was mit den Daten passieren sollte…
Nachdem ich mehrere Versuche enttäuscht abgebrochen hatte, war es Claude wo das erste mal „Das hilft mir!“ am Ende heraus kam. Dann hat Gemini aufgeschlossen und manches, woran Claude gescheitert ist, hat dann Gemini hinbekommen. Eine Zeit lang habe ich dann beide genutzt, in letzter Zeit aber vor allem Gemini, weil Claude da wo Gemini nicht weiter wusste meistens auch gescheitert ist. Jetzt werde ich das wohl mal wieder stärker einbeziehen…
Diese ganzen „Benchmarks“ kommen mir komisch vor. Kann es sein, dass die KIs wissen, dass sie diese Benchmarks lösen können sollen? So manches Benchmark-Ranking deckt sich überhaupt nicht mit meinen Erfahrungen aus der Praxis.