Nvidia Chat With RTX: Offline-KI hilft bei Dateisuchen und mehr
![]() von Benjamin Mamerow | 3 Kommentare
von Benjamin Mamerow | 3 Kommentare
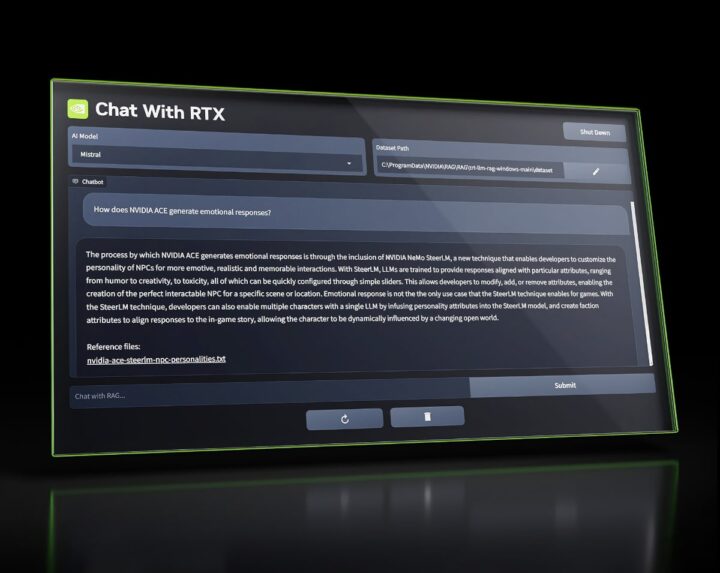
Nvidia bietet mit Chat with RTX nun eine Offline-KI an
Nvidia hat seine Offline-KI „Chat With RTX“ veröffentlicht, die es ermöglicht, die Leistungsfähigkeit eines GPT-LLM (Large Language Model) mit euren eigenen Inhalten zu kombinieren. Dokumente, Notizen, Videos oder andere Daten – lassen sich mit Chat With RTX in ein personalisiertes Sprachmodell integrieren, das auf Knopfdruck kontextbezogene Antworten liefern soll. Es handelt sich hierbei allerdings auch erst einmal nur um eine Demo-App.
Schnelle Antworten dank RTX-Beschleunigung
Die Anwendung nutzt die Retrieval-Augmented Generation (RAG)-Technologie, um Anfragen möglichst effizient zu beantworten. In Kombination mit der TensorRT-LLM-Optimierung und der RTX-Beschleunigung von Nvidia GPUs verspricht das für RTX-Nutzer eine flotte Verarbeitung der Anfragen. Die App unterstützt eine Vielzahl von Dateiformaten, darunter Text, PDF, DOC/DOCX und XML. Durch Verweisen auf Ordner mit euren Daten werden diese automatisch in die Bibliothek der Anwendung geladen. Auch Transkriptionen von YouTube-Videos können in Chat With RTX integriert werden. Gebt dazu einfach die URL an und die App lädt die Transkripte herunter. Alle Daten werden lokal auf dem PC verarbeitet und nicht in eine Cloud gesendet.



Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.
Also schnell ist es. Das liegt aber nicht zwangsläufig an der Hardware, sondern an dem doch realtiv kleinen Mistral (7B) Modell. Ich habe vor einigen Tagen GPT4ALL getestet und die Geschwindigkeit war nahezu identlisch. Der Nachteil den ich bei Chat with RTX empfand war, dass ich keinen „System Prompt“ vorgeben konnte und so alle Antworten (auch auf deutschsprachigen Input (PDF, DOC)) immer Englisch waren (auch mit Befehl „Schreibe auf Deutsch!“ im Prompt). Nicht schlimm, aber auch nicht toll.
Mit GPT4ALL kann ich auch Mixtral Modelle verwenden, die nochmal wesentlich besser sind (Logik, Verständnis, Konversation) – aber leider langsamer. Eine echte GPU Beschleunigung (auch Tensor Kerne BTW), gibt es mit GPT4ALL v2.7 aktuell (für Mixtral Modelle) noch nicht, llama.cpp hat dies aber schon integriert. Ist somit nur eine Frage der Zeit.
Und ja. Ein wenig Wumms braucht die Grafikkarte auch hier. Mit 24GB kommt man lokal schon recht weit, alternativ kann man sich aber auch was in der Cloud provisionieren. Da kann man für kleines Geld mal vorher testen.
TL;DR: GPT4ALL ausprobieren!
Danke für deine Vergleiche 🙂 Zu welcher Lösung / Kombination sollte ich denn nun deiner Meinung nach am besten greifen, wenn ich RTX 4090-Besitzer bin und es lokal halten möchte?
Ich selbst habe eine 4090 und würde Dir zu GPT4ALL mit Mistral raten (was dann identisch wäre wie Chat with RTX, jedoch mit Vorteilen wie „System Prompts“ und mehr Einstellungsmöglichkeiten. Leider läuft Mixtral (wie erwähnt) noch nicht auf der GPU (sondern scheinbar auf CPU – so jedenfalls die Anzeige und Kommentare bei Github). Wird aber bestimmt noch kommen. 🙂