Google Research Labs schafft Durchbruch bei der Erforschung von maschineller Bildbeschreibung
von Pascal Wuttke | 12 Kommentare
Das Google Research Lab hat bekannt gegeben, dass man einen neuen Durchbruch in der automatisierten, computergenerierten Bildbeschreibung erlangt hat. Mithilfe jüngster technischer Fortschritte hat man ein maschinelles Lernsystem entwickelt, dass den Inhalt von Bildern interpretiert und eine passgenaue Bildbeschreibung ausspuckt.

Während das menschliche Gehirn ohne weiteres in der Lage ist, den Inhalt eines Bildes zu analysieren und eine treffende Bildinhaltsangabe erstellen kann, ist dies bei Computern denkbar schwieriger. Hierfür hat Google hat sich die jüngsten Fortschritte in der maschinellen Objekterkennung, Klassifizierung und Kategorisierung als Grundlage für den neuesten Forschungsansatz herangezogen.
Bisher gingen die Versuche dahin, verschiedene Bilderkennungsalgorithmen und natürlich Sprachverarbeitungsprozesse nebeneinander laufen zu lassen, um eine Bildbeschreibung zu erhalten. Doch Google versucht hier diese beiden Prozesse in ein einzelnes Verarbeitungssystem zu packen, sodass beispielsweise ein soeben geschossenes Bild direkt mit einer menschlich verständlichen Bild-Inhaltsbeschreibung versehen wird. Fotografiert Ihr also eine zwei Pizzas, die auf den Ofen zum abkühlen gestellt wurden, so interpretiert der Algorithmus den Inhalt des Bildes und gibt „Two pizzas sitting on top of a stove top oven“ als Bildbeschreibung aus.

Dafür nutzt Google die jüngsten Fortschritte in der Maschinen-Übersetzung, bei der ein „Recurrent Neural Network (RNN)“ beispielsweise einen französischen Satz in eine Vektordarstellung umwandelt, während ein zweites RNN diese Vektordarstellung nutzt, um einen Zielsatz auf deutsch zu generieren. Dann wird das erste RNN und die eingegebenen Worte durch ein „deep Convolutionals Neural Network (CNN)“ oder zu deutsch „faltendes neurales Netzwerk“ ersetzt und auf eine Bild-Objekt-Klassifizierung trainiert.
In der Regel wird die letzte Schicht des CNN genutzt, um mit einer mathematischen Formel (Softmax) die Wahrscheinlichkeit zu erkennen, ob sich weitere Objekte im Bild befinden und welcher Klassifizierung diese angehören. Diese letzte Schicht wird in Googles Methodik entfernt in ein RNN umgewandelt, dass Sätze produziert. Wenn das gesamte System auf diesen Ablauf trainiert ist, erhöht sich die Wahrscheinlichkeit, dass es auch bei anderen Bildern eine ähnlich hohe Genauigkeit aufweist, wie in den Trainingsszenarios.

Google hat nach eigenen Angaben mit diesem System verschiedenste öffentlichen Datensätze durchlaufen lassen, wie zum Beispiel Pascal, Flickr8k, Flickr30k und SBU. Das Bild unten zeigt, wie genau Googles Erkennungssystem tatsächlich ist und dass es verständliche Sätze formulieren kann.
Googles Forschung an der maschinellen Erstellung von Bildbeschreibung soll Euch natürlich nicht nur die Bildbeschreibung für Eure Instagram-Fotos vereinfachen, sondern insbesondere hilfreich für Menschen mit eingeschränktem Sehvermögen sein.




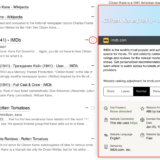

Ich mag Pizza.
Mit Sicherheit auch für den Google-Algorithmus nicht uninteressant.
Horst Zuse (Sohn von Konrad Zuse) forscht an der TU Berlin genau in diese Richtung. Wäre mal interessant, ob die da im Austausch stehen. Ich hab 2008 eine Demo der Software gesehen. War zwar noch rudimentär, trotzdem schon sehr beeindruckend.
vor allem auch später für videos interessant wenn dann videos automatisch analysiert werden, person macht dies und das ect.
Na da wird sich sicherlich bald das FBI für interessieren, wenn die nich schon jetzt ihre Kraken ausgefahren haben.. Als nächstes werden automatisch Bilder von öffentlichen Plätzen ausgewertet und eine Kamera schlägt Alarm mit der Mitteilung „Zwei Menschen werfen Flaschen“ oder am Flughafen um verdächtige Situationen gleich zu erkennen..
Ich gebe hier Patrick Recht. Auch bzgl. SEO könnte dies enorme Auswirkungen haben.
@Speedster,
der gute Mann w a r mal an der TUB (bis 2008?). Jetzt gibt er dort nur noch ab und an einen Kurs, ist aber hauptsächlich an einer anderen Uni.
@caschy: Ha! Multiplicity-Zitat? Ich muss heute noch jedesmal den Spruch sagen wenn ich Pizza esse. (Ui, sehe gerade, dass der Film 18 Jahre alt ist… Tempus fugit)
@Peter Baum: Nope, das Pizza-Beispiel ist tatsächlich von Google übernommen, daher auch das Bild mit den Leckereien 🙂
Neee, ich meinte nicht das Bild sondern Caschys Satz dazu: „Ich mag Pizza“.
Vielen Dank! Machine Learning war vor kurzem auch Thema einer Blogparade der bitkom, hier z.B. http://blogs.sas.com/content/sasdach/2014/10/09/zukunft-des-wissensmanagements-cognitive-computing/. Der Beitrag hätte da wirklich gut reingepasst.
Soso, das semantische Web 3.0 kommt nun also doch in die Gänge. Mein Gott, ich dachte schon, die Entwicklung wäre dank des Social-Media-Hype komplett eingeschlafen 🙁